(논문 요약) FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision (Paper)
핵심 내용
- Nvidia Hopper H100 GPU 에서 효율적인 연산을 하기 위한 기법들 (최대한 parallel 하게 연산)
- Producer-Consumer asynchrony: split producers and consumers of data into separate warps
- Hiding softmax under asynchronous block-wise GEMMs (General Matrix Multiply): overlap low-throughput non-GEMM operations in softmax with asynchronous WGMMA (Warpgroup Matrix-Multiply-Accumulate) instructions for GEMM.
- Hardware-accelerated low-precision GEMM: make use of FP8 Tensor Cores for GEMM
배경 지식
- Memory hierarchy
- Global memory (GMEM): a.k.a HBM, 각 streaming multiprocessor (SM) 가 접근 가능한 off-chip DRAM
- shared memory (SMEM): 각 streaming multiprocessor 내부의 on-chip cache
- Register file (RMEM): 각 thread 내부에 존재
- Thread hierarchy
- warps: 32 threads
- warpgroups: 4 contiguous warps
- threadblocks: a.k.a cooperative thread arrays or CTAs
- Threads in the same CTA are co-scheduled on the same SM
- CTAs in the same cluster are co-scheduled on the same GPC

알고리즘
- Producer-Consumer asynchrony: pingpong 으로 서로 다른 warpgroup 이 softmax 와 GEMMs (General Matrix Multiply) 교차
- producer: HBM 에서 shared memory 로 데이터 복사
- consumer: 복사된 데이터로 연산
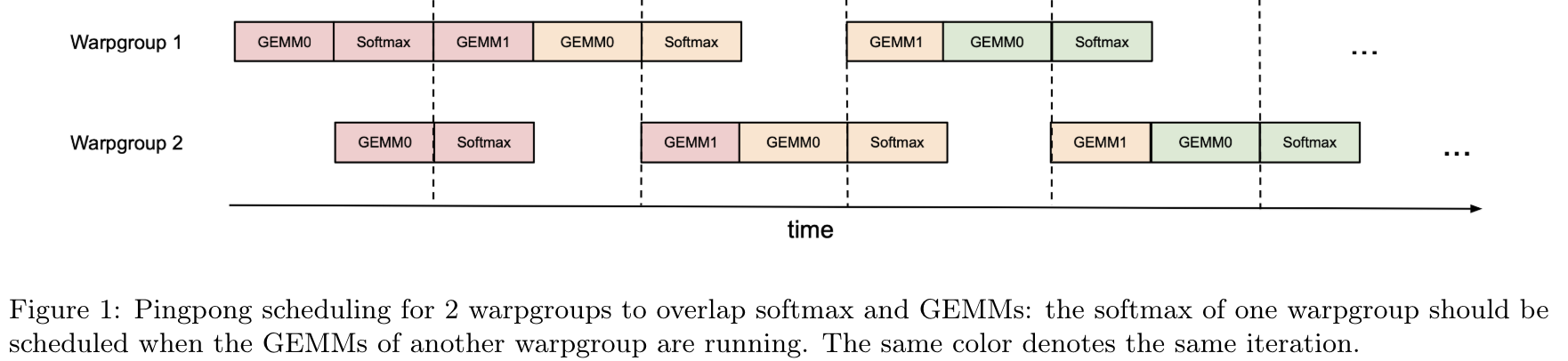

- consumer 의 warpgroup 내에서 추가적인 병렬화
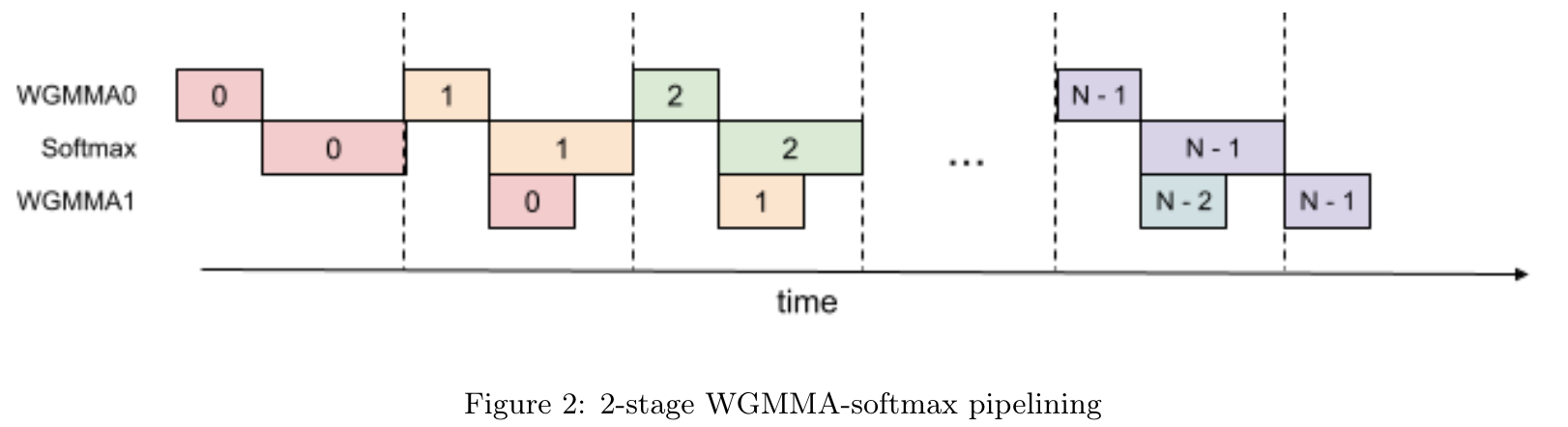
- 위의 알고리즘에서 local softmax 연산 (line18-19) 는 $S^{(j)}_i$ 가 끝나야함
- 해당 local softmax 결과는 line21 에서 사용됨
- 위의 2개 operation 을 쪼갬
- softmax 연산과 WGMMA (Warpgroup Matrix-Multiply-Accumulate) 을 교차

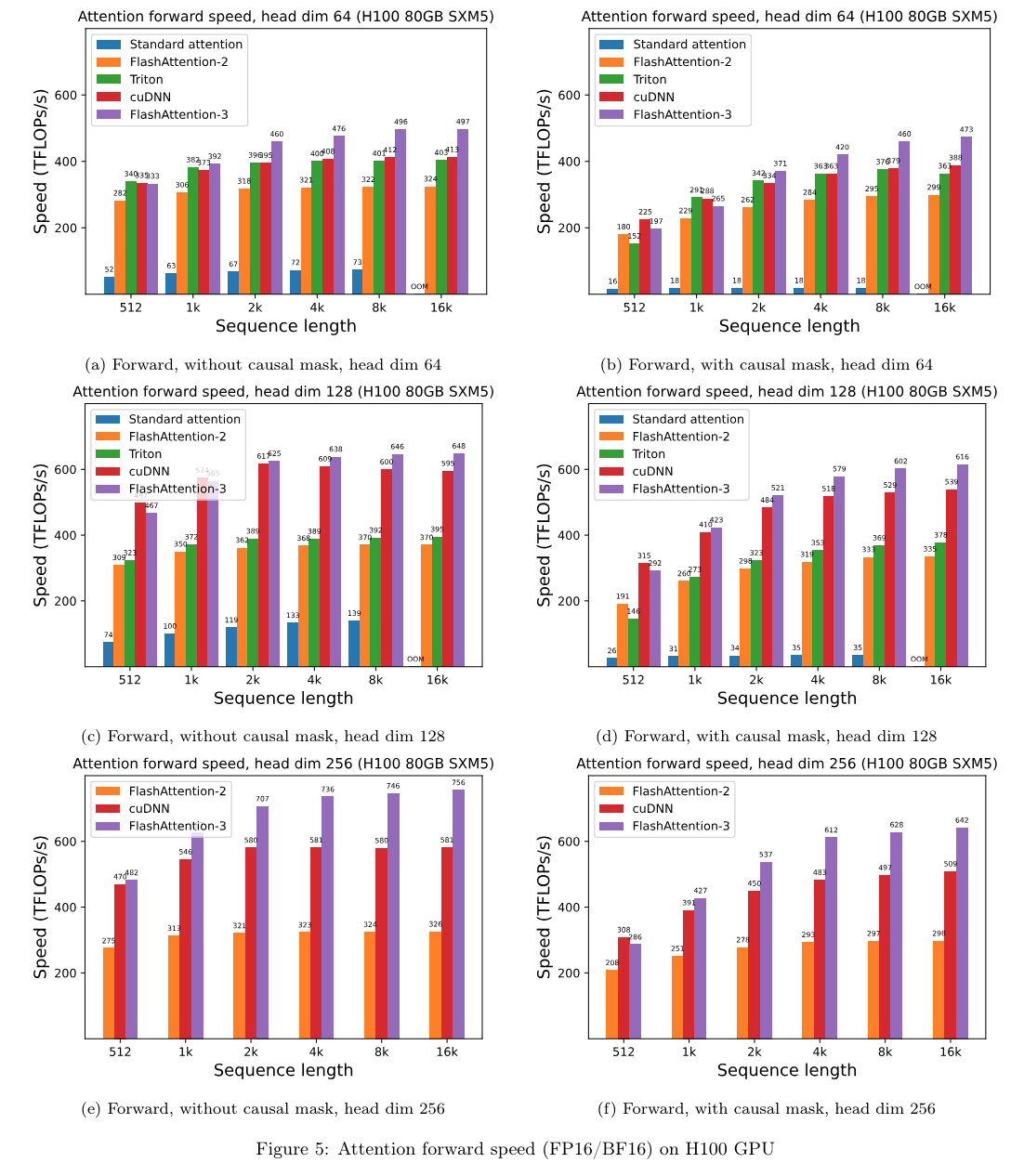
실험 결과