(논문 요약) EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty (paper)
핵심 내용
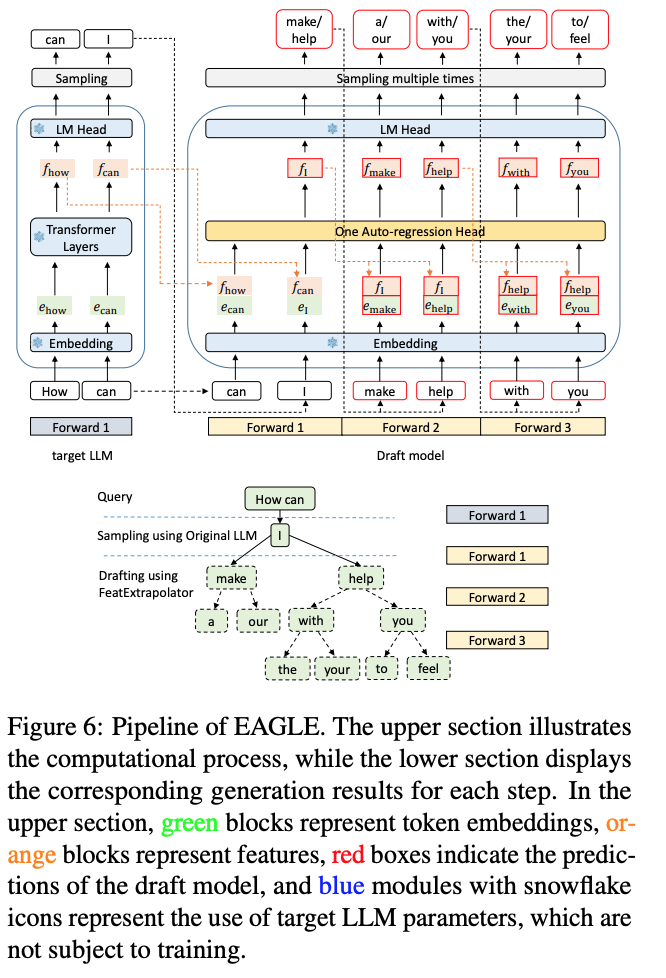
- Draft model
- target LLM 의 LM Head, Embedding layer 사용
- One Auto-regression Head == FC + single decoder.
- input: token + feature
- output: feature
- next token: top-$k$ 혹은 $k$ samples from softmax distribution
- tree attention: 생성된 토큰의 tree 구조에서 ancestor 만 attention
- speculative decoding 시 tree attention 사용하고 매 $s$ step (실험에서는 $s$=5) 마다 target LLM 으로 verify.
- target LLM probability 를 $p$, draft model 의 probability 를 $q$ 라 할때,
- 현재 node ($q$ 가 높은순 혹은 random) 를 $\min(1, p/q)$ 확률로 accept
- accept 시 child node 로 넘어감.
- reject 시 같은 depth 의 다른 node 로 넘어감.
- 모든 노드가 reject 된 경우, target LLM 이 생성.