(논문 요약) Extreme Compression of Large Language Models via Additive Quantization (paper)
핵심 내용
- generalizes the classic Additive Quantization
- learned additive quantization of weight matrices in input-adaptive fashion
- joint optimization of codebook parameters across entire layer blocks (using calibration data)
- additive quantization
- weight matrix 를 contiguous rows ($g$줄) 단위로 자름
- 각 codebook 에는 $B$-bit code 가 존재 ($2^B$ vectors representable)
- 각 codebook 에서 code 를 하나씩 뽑아서 더해서 $g$줄을 표현
- 기본 최적화 식:
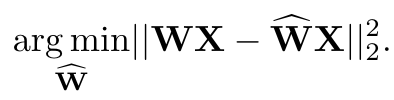
- For $i$th output unit, group $g$ input units
- one-hot-vector $b_{ijm}\in R^{2^{B}}$, $M$ codebooks ($C_1$,…,$C_M$)

- 변경된 최적화 식:
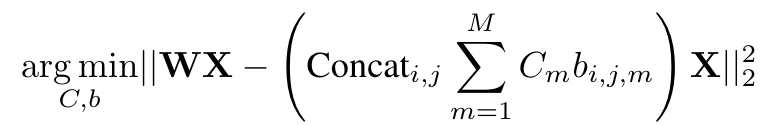
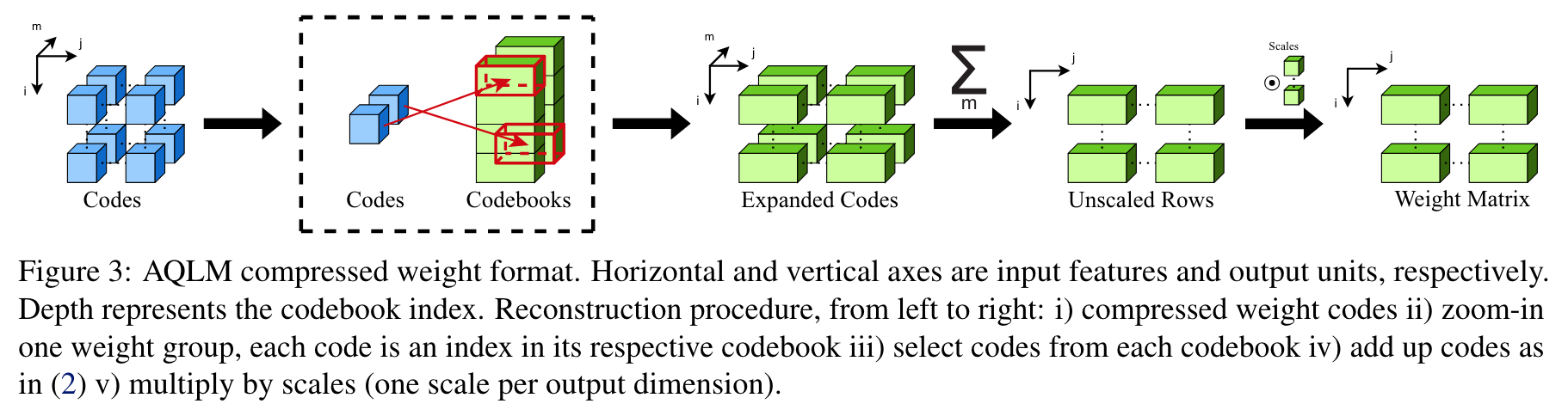
- weight reconstruction process
- algorithm
- 각 layer 별로 code ($b_{ijm}$) 와 codebooks ($C_m$) 을 번갈아가며 학습
- codebook update (train_Cs_adam): $b_{ijm}$ 고정, codebooks, scale vectors, RMSNorm scales, biases 학습
- beam search: $b_{ijm}$ 을 Markov Random Field solver 로 최적화

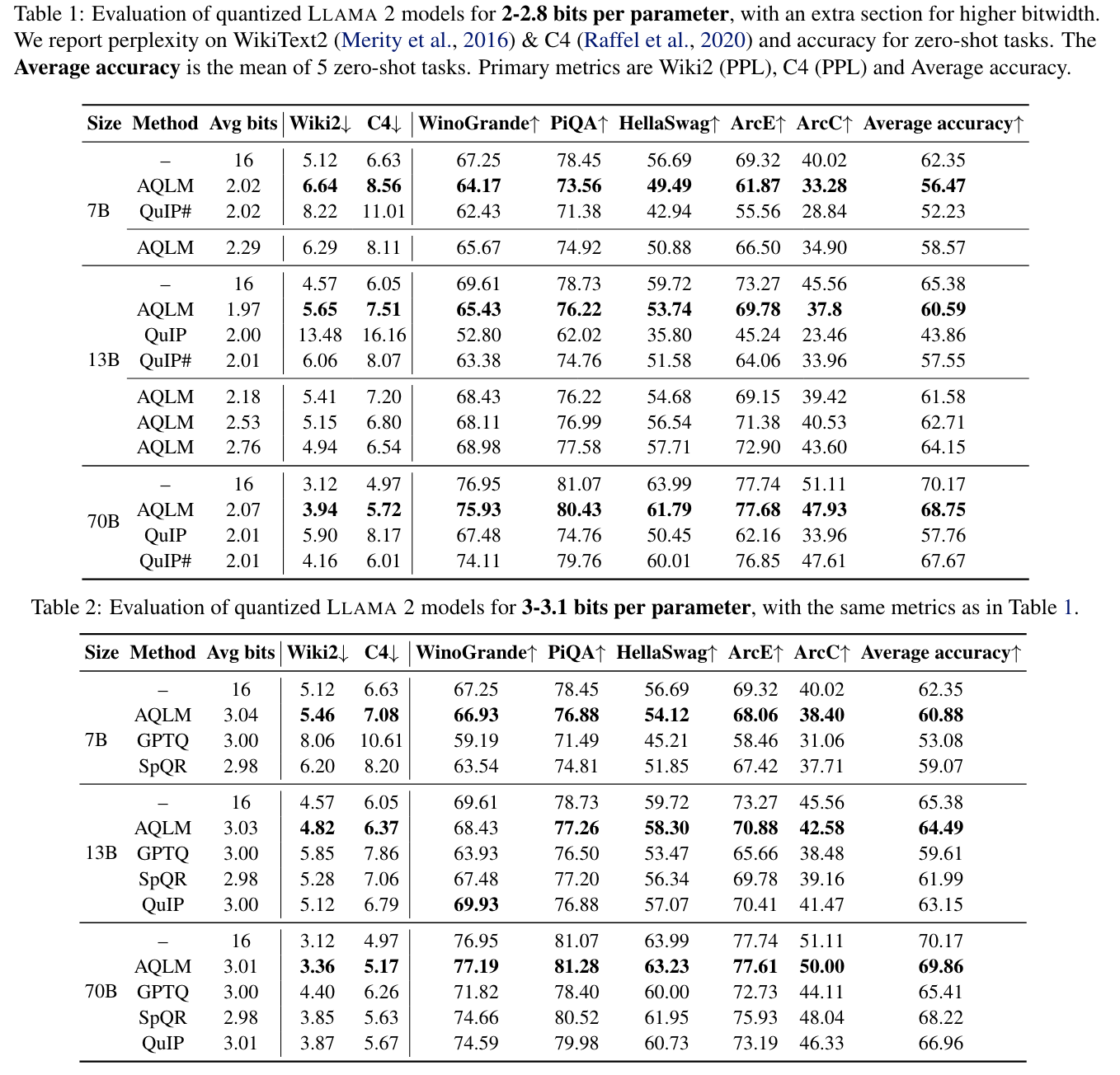
실험 결과
- 성능 비교
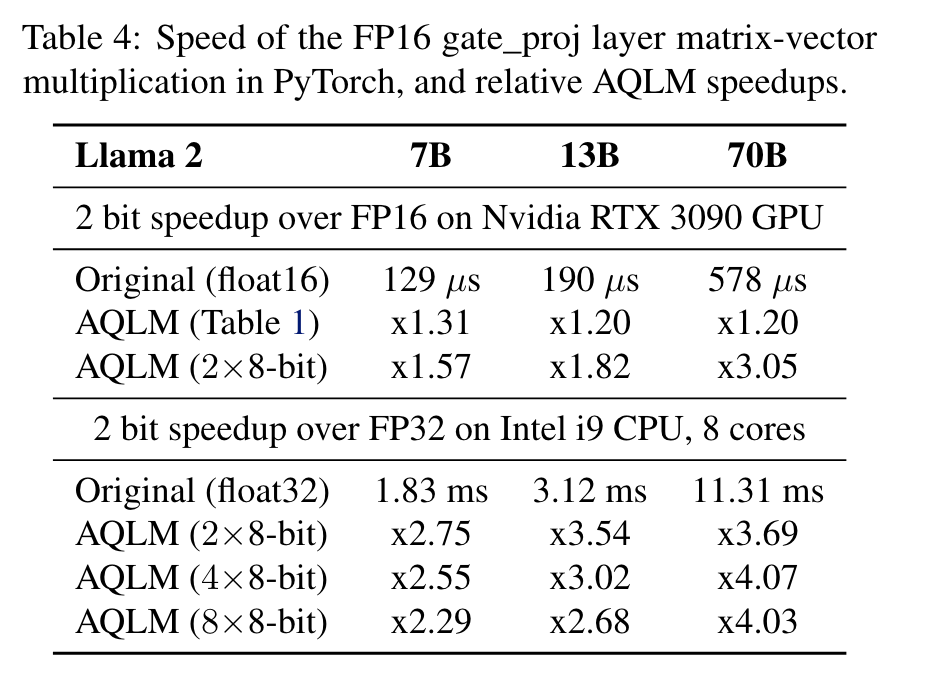
- 속도: authors implemented efficient GPU and CPU kernels for a few hardware-friendly configurations of AQLM