(논문 요약) TULU 3: Pushing Frontiers in Open Language Model Post-Training (Paper)
핵심 내용
- Data, code, and training recipes 모두 공개
- 모델: Llama 3.1 기반
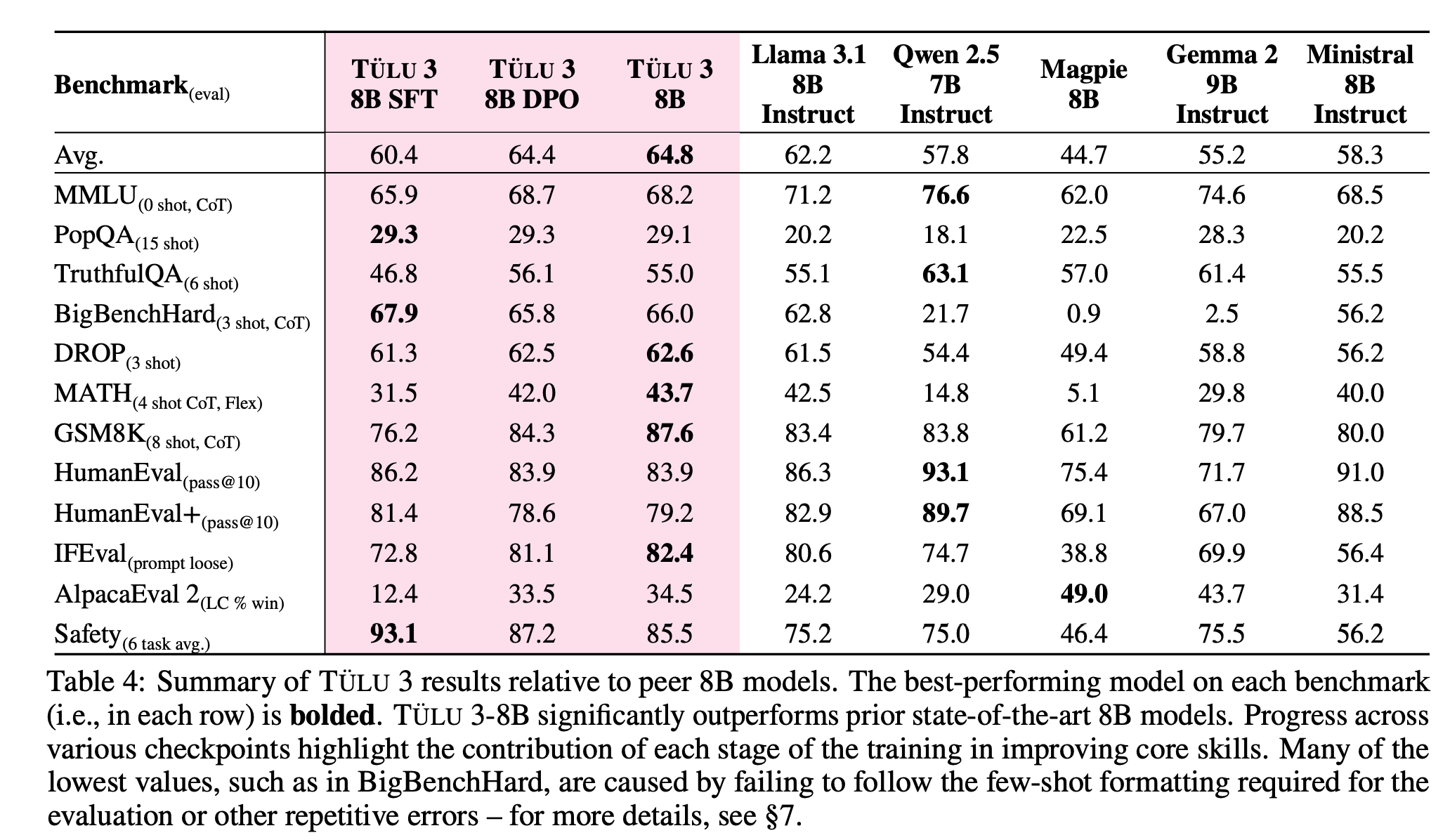
학습 순서
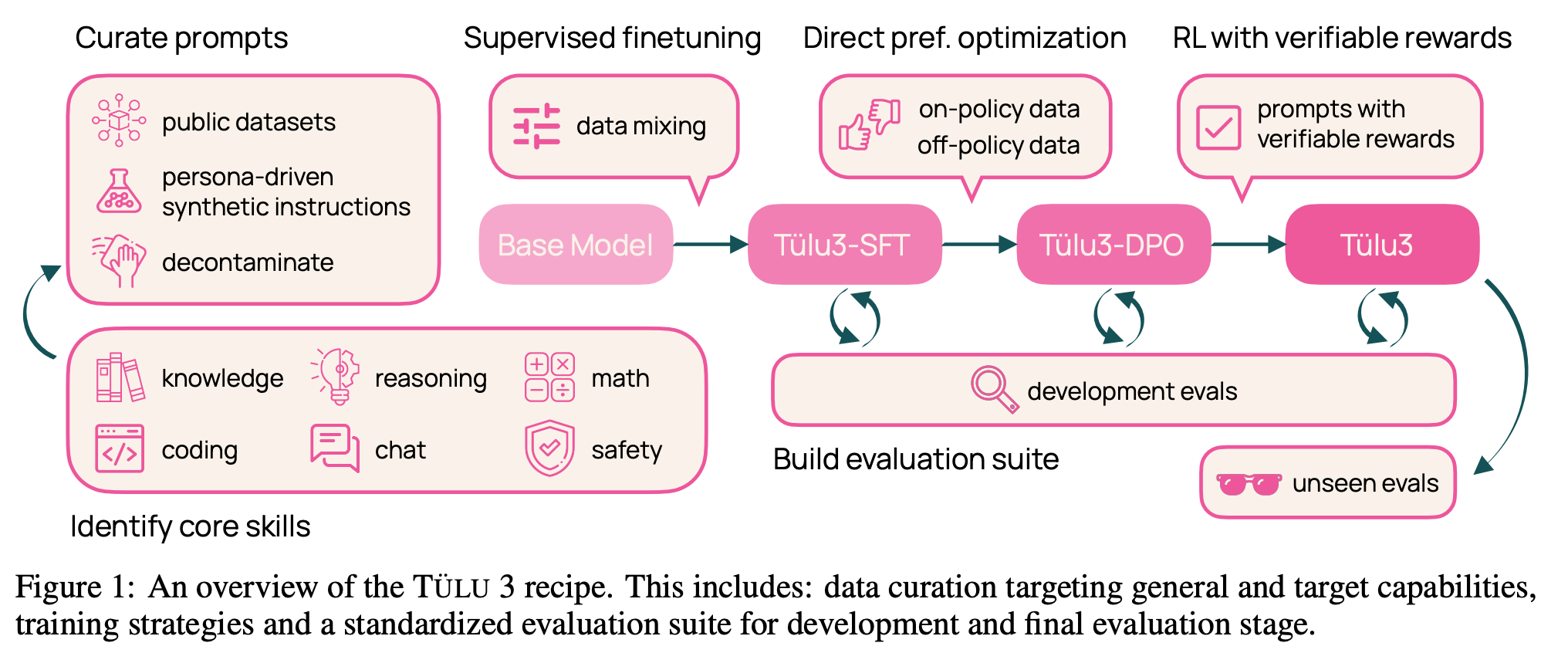
- Reinforcement Learning with Verifiable Rewards
- LLM 의 마지막 답변이 맞는 경우 reward=10, 아닌 경우 0
- PPO algorithm 사용
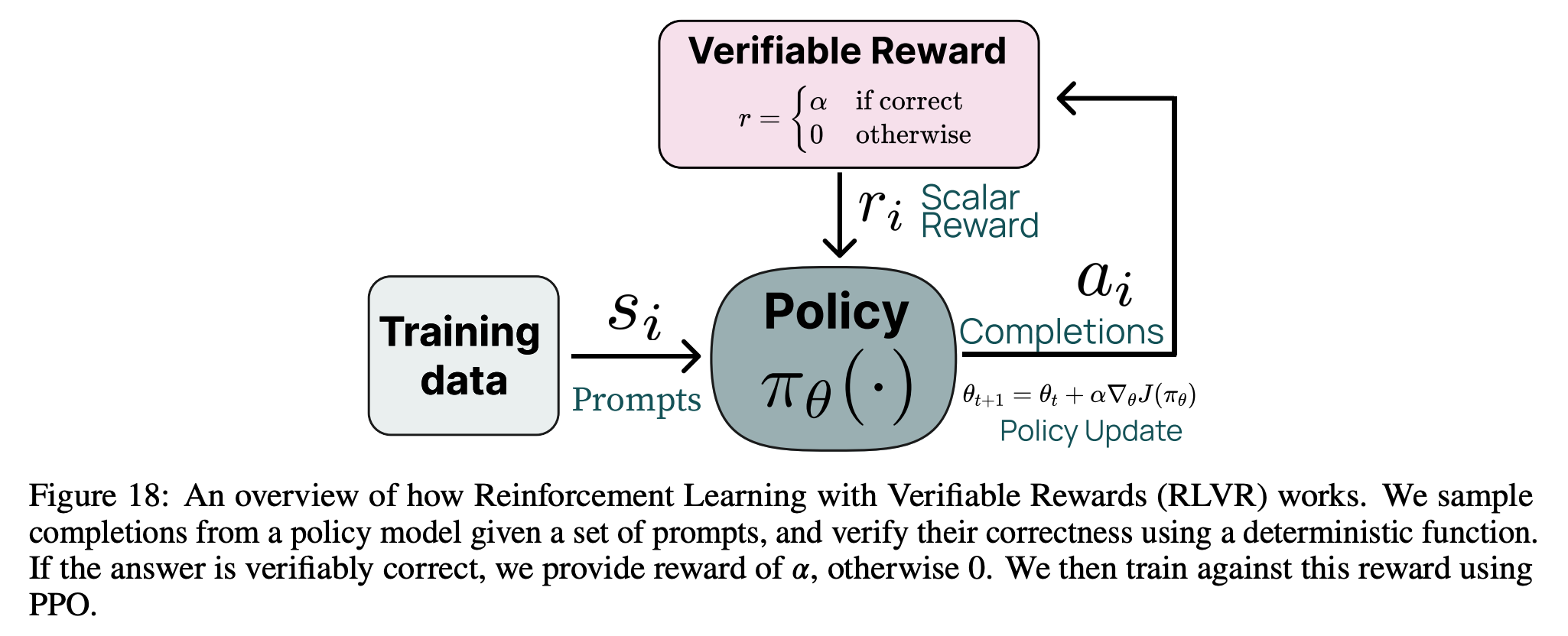
실험 결과