(논문 요약) Sky-T1: Train your own O1 preview model within $450 (blog)
핵심 내용
Qwen QwQ 모델로 데이터 모아서 Qwen-Instruct 모델 SFT.

- Data
- 17K (5k from APPs and TACO, 10k math data from AIME, MATH, and Olympiads subsets of the NuminaMATH, 1k science and puzzle data from STILL-2)
- QwQ-32B-Preview 로 traces 생성 후, GPT-4o-mini 로 reformat.
- Rejection Sampling: 수학은 정답 맞는 trace, 코드는 execute 가능한 것들만 학습에 사용.
- Train
- 3 epochs
- learning rate 1e-5
- batch size 96
- 19 hours on 8 H100 with DeepSpeed Zero-3 offload
- Findings
- 7B, 14B sLM 으로 성능 향상 없었음.
- 3–4K math data 로 학습 후, code data 학습 시 성능 하락. math data 와 code data 늘려서 학습 시 둘 다 성능 향상.
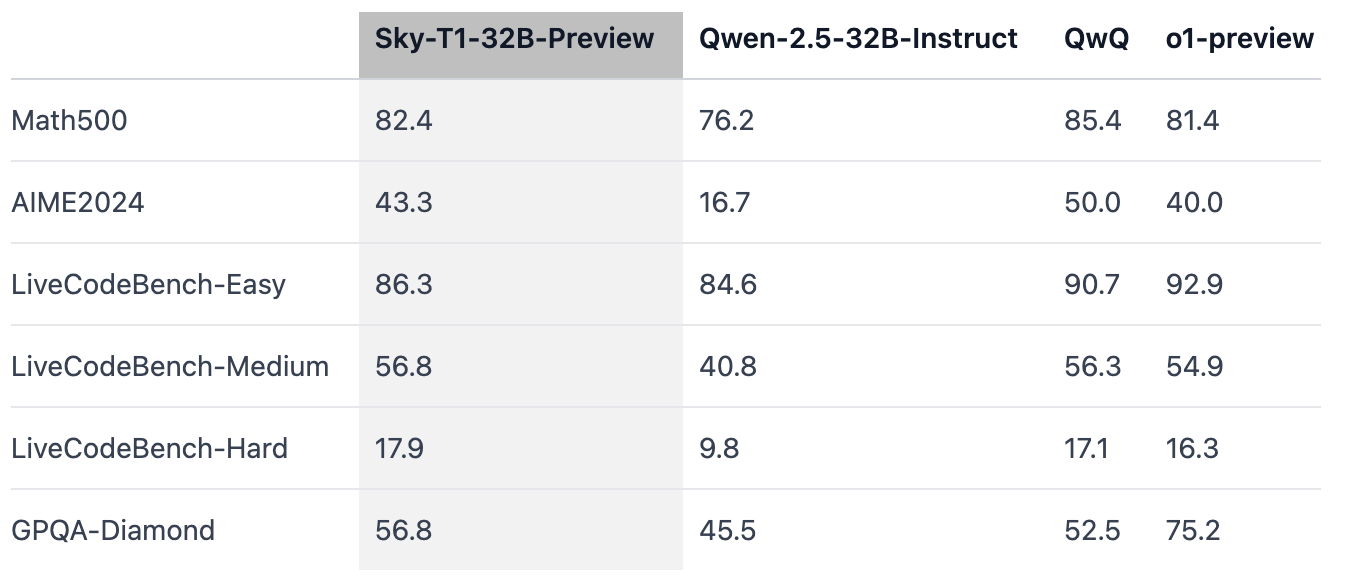
실험 결과