(논문 요약) rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking (paper)
핵심 내용
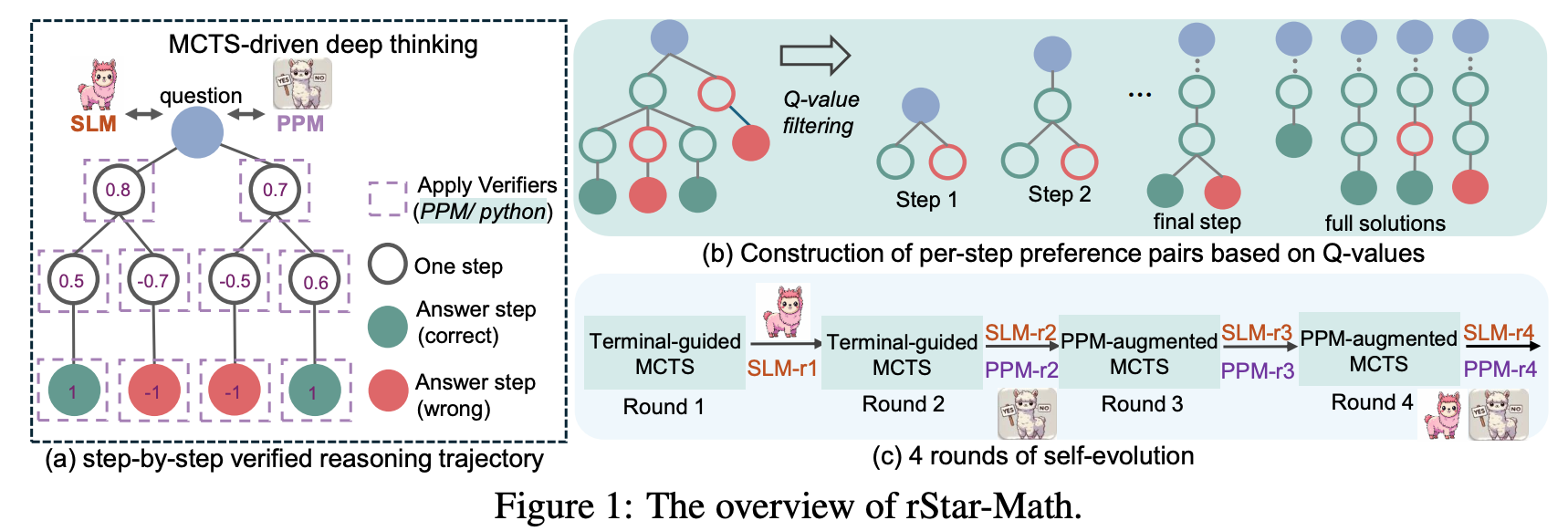
- python code + comment 인 CoT data 생성.
- 돌아가는 code 만 node 로 남김.
- Q-value 계산하여, MCTS 로 sample.

- Q-value 계산
- Terminal-guided annotation (1,2 round): terminal node 에서 맞으면 1, 틀리면 -1, intermediate node 는 backprop 으로 update.
- process preference model (3,4 round): 맞는 trajectory, 틀린 trajectory 쌍으로 preference training (Bradley-Terry).
- 데이터
- 747k math word problems with final answer ground-truth labels, primarily from NuminaMath and MetaMath.
- GPT4 생성 데이터: seed 문제들에 대해서 생성한 뒤, 10번 중 3번 맞추는 문제들 사용
- SLM finetuning: 가장 Q-value 높은 2개 trajectories 로 학습.
- PPM initial weight: finetuned 된 SLM 의 prediction head 만 linear + tanh 로 변경.
실험 결과
Trajectories: 16 for AIME/AMC and 8 for other benchmarks, using PPM to select the best solution.

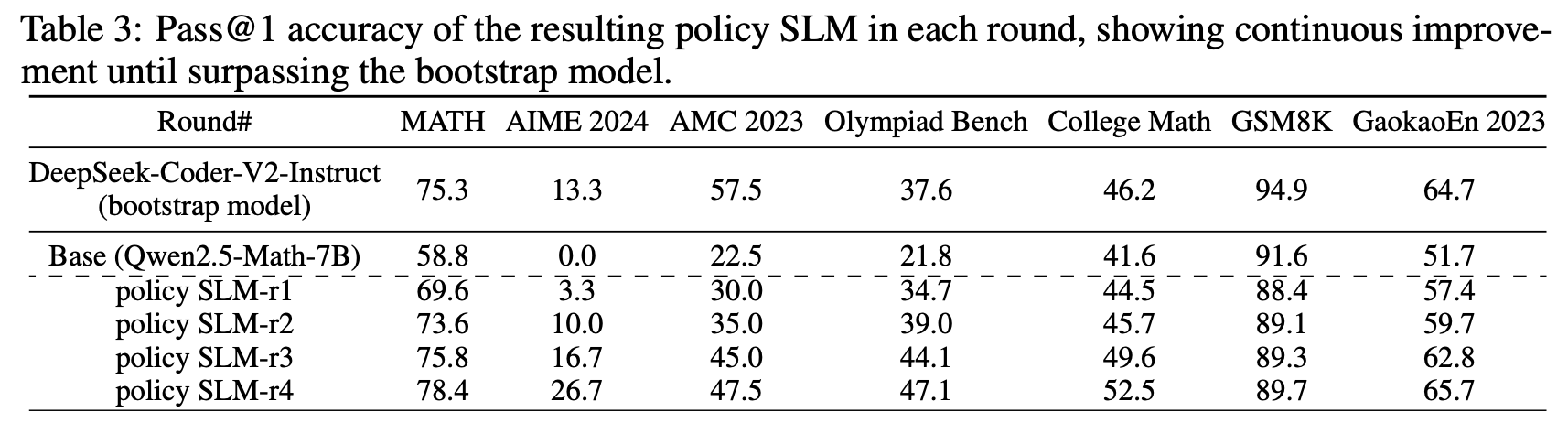
Iterative training 으로 성능 점진적으로 향상