(논문 요약) Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? (paper)
핵심 내용
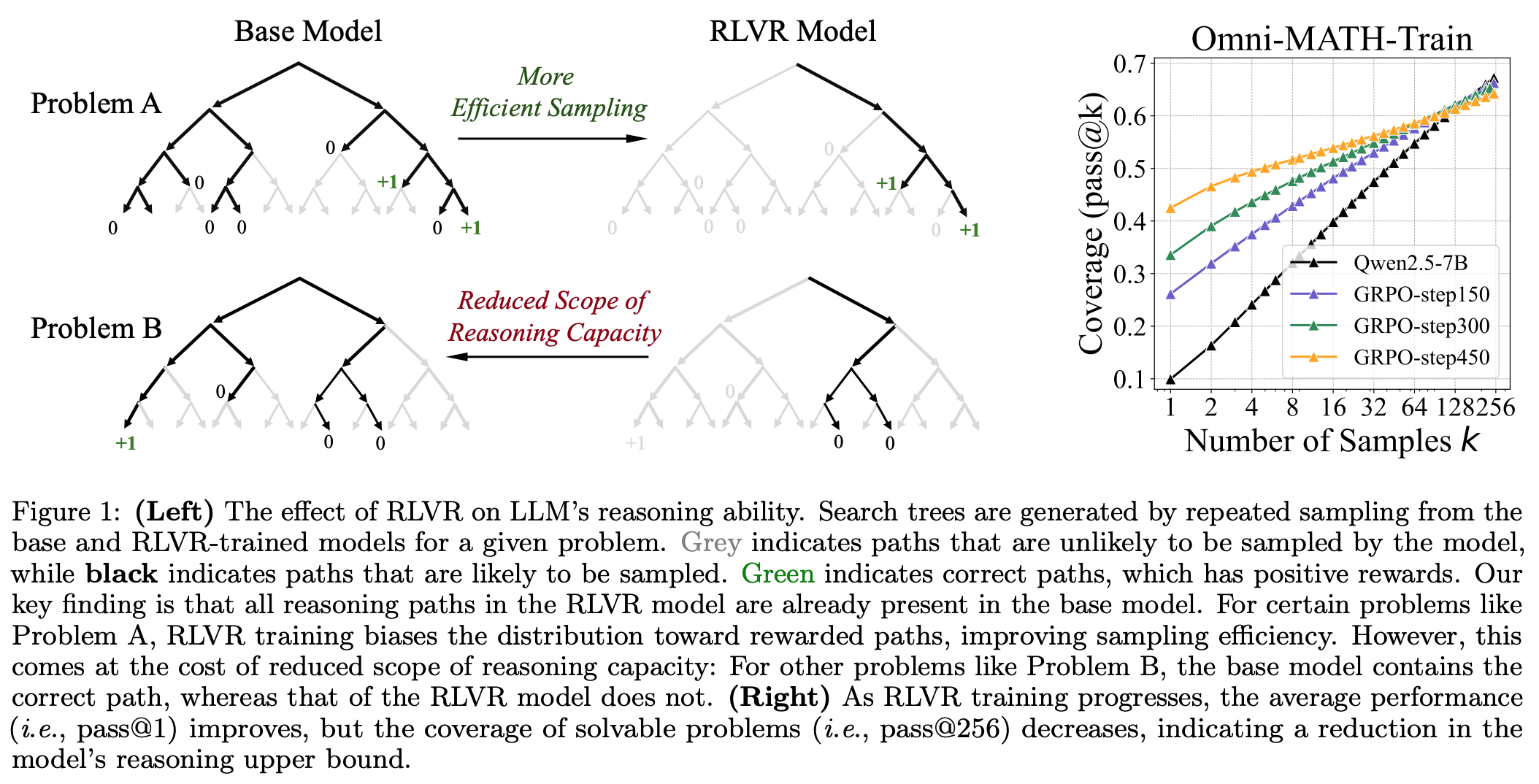
- RLVR (Reinforcement Learning with Verifiable Rewards) 는 base model 의 exploration 을 억제하여 sampling efficiency 를 높여줌.
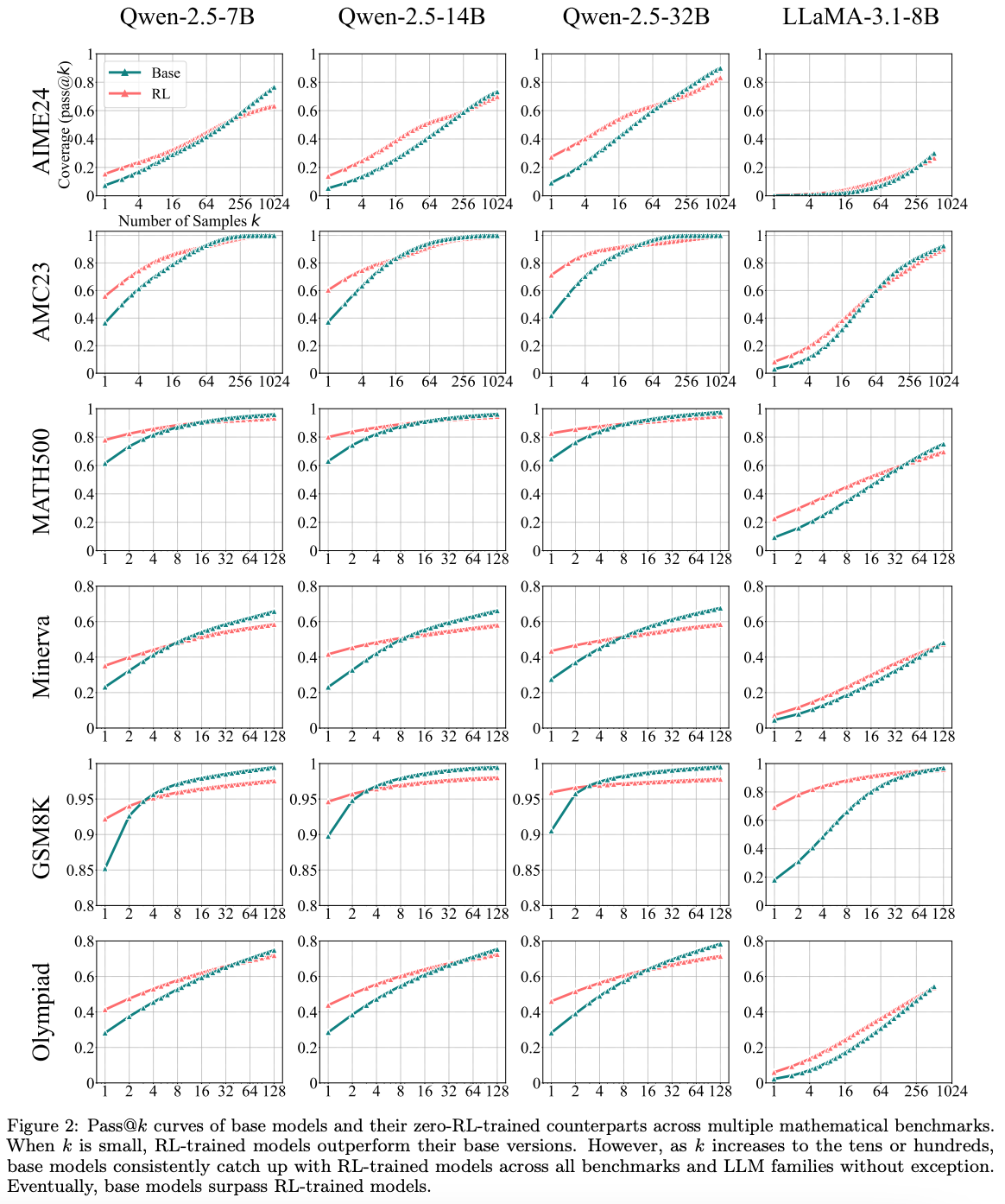
- 여러 모델에서 비슷한 경향성 관찰됨.
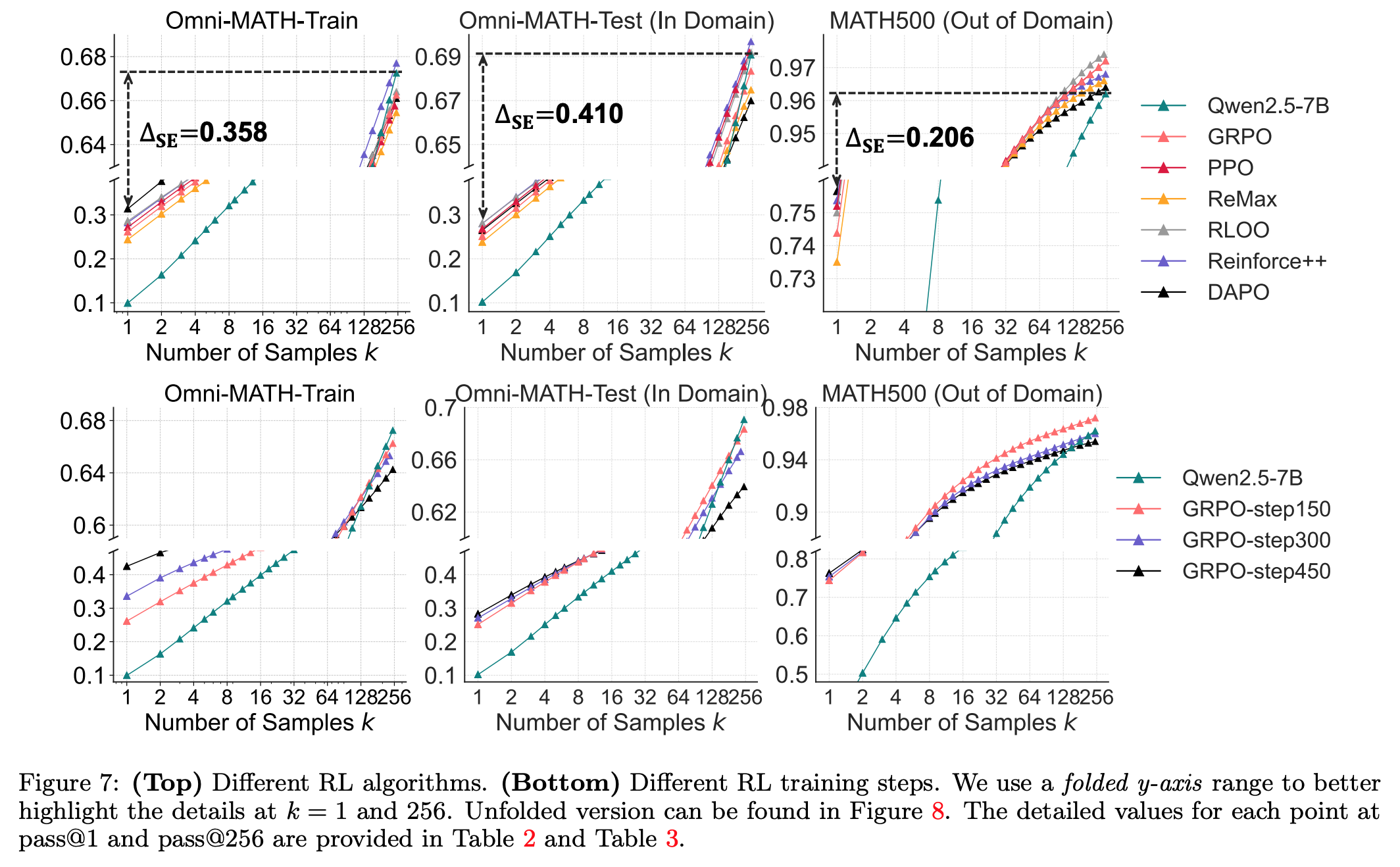
- 다른 RL methods 에서도 같은 현상이 발견됨.
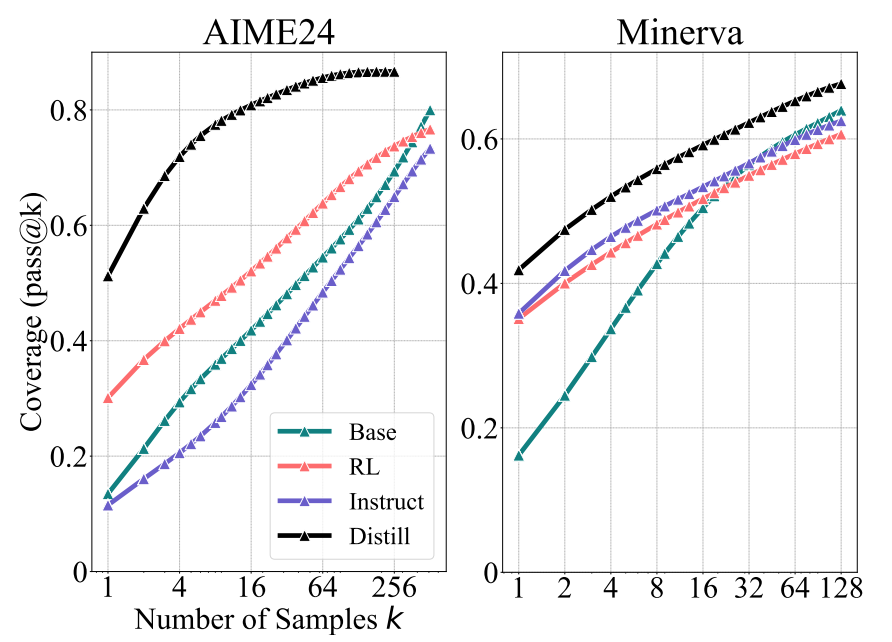
- distillation 은 모델의 성능을 향상시키는 듯함.