(논문 요약) Reinforcement Learning for Reasoning in Large Language Models with One Training Example (Paper)
핵심 내용
- 데이터 1개로 RLVR 돌려도 수천개 데이터로 돌린 것과 비슷한 효과를 볼수 있음.
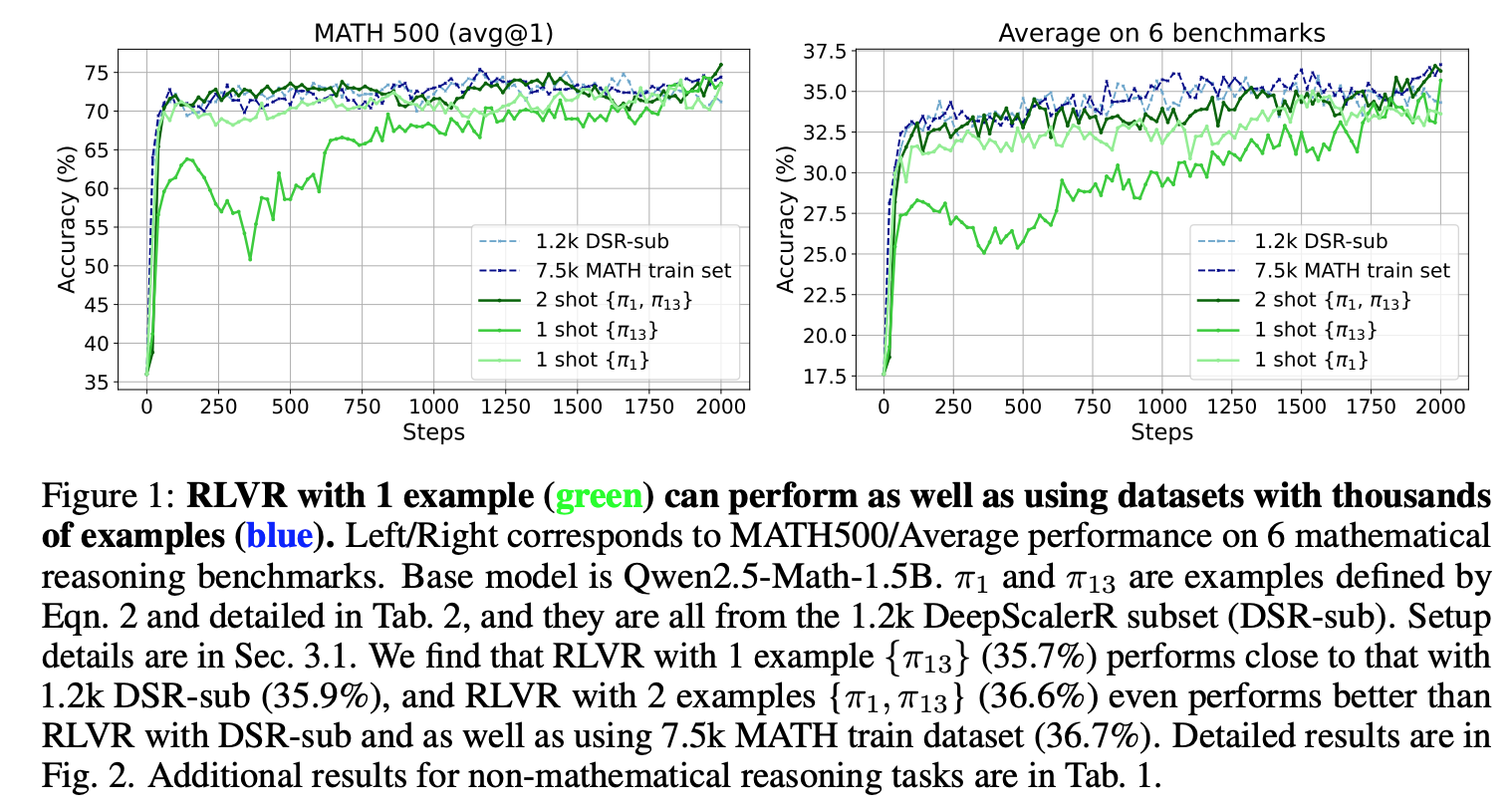
실험 결과
- $\pi_j$: 각 데이터별 training accuracy 의 분산이 큰 순서로 sort 한뒤 $j$ 번째 element.
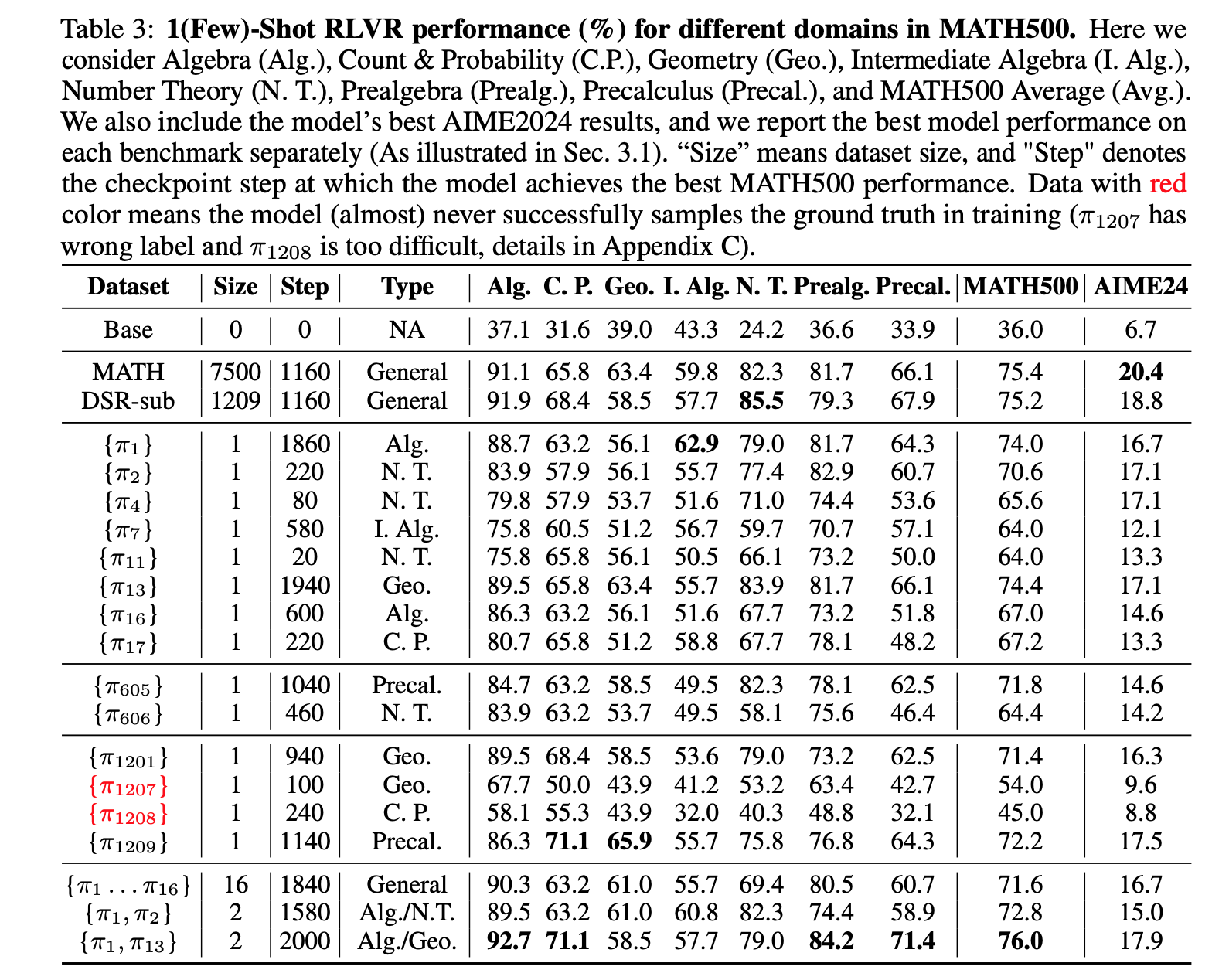
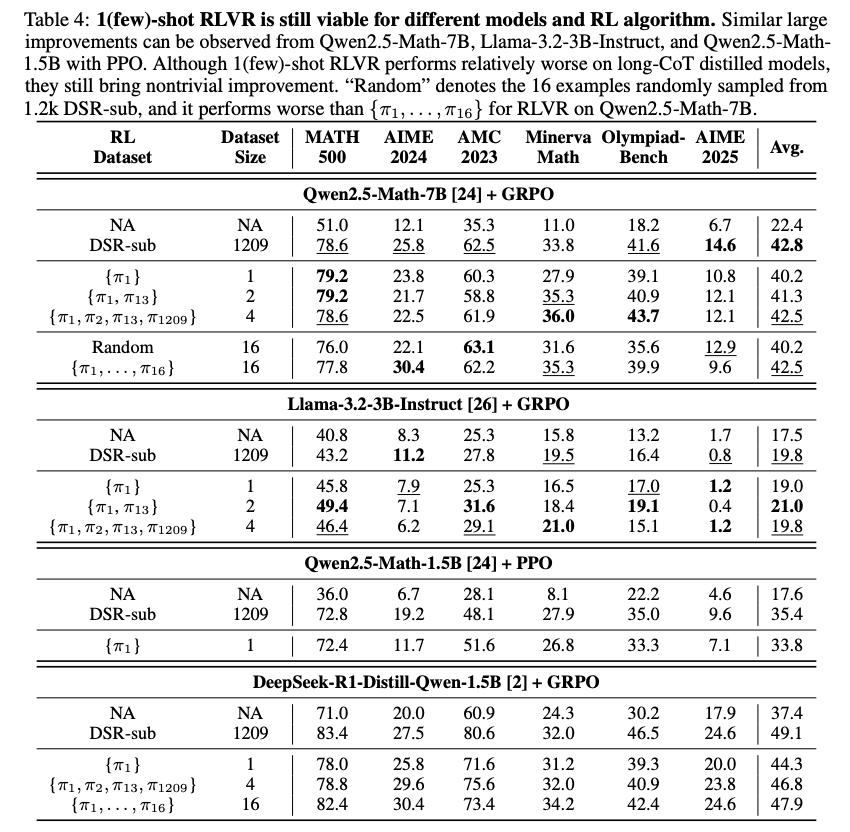
(논문 요약) Reinforcement Learning for Reasoning in Large Language Models with One Training Example (Paper)