(논문 요약) Spurious Rewards: Rethinking Training Signals in RLVR (Paper)
핵심 내용
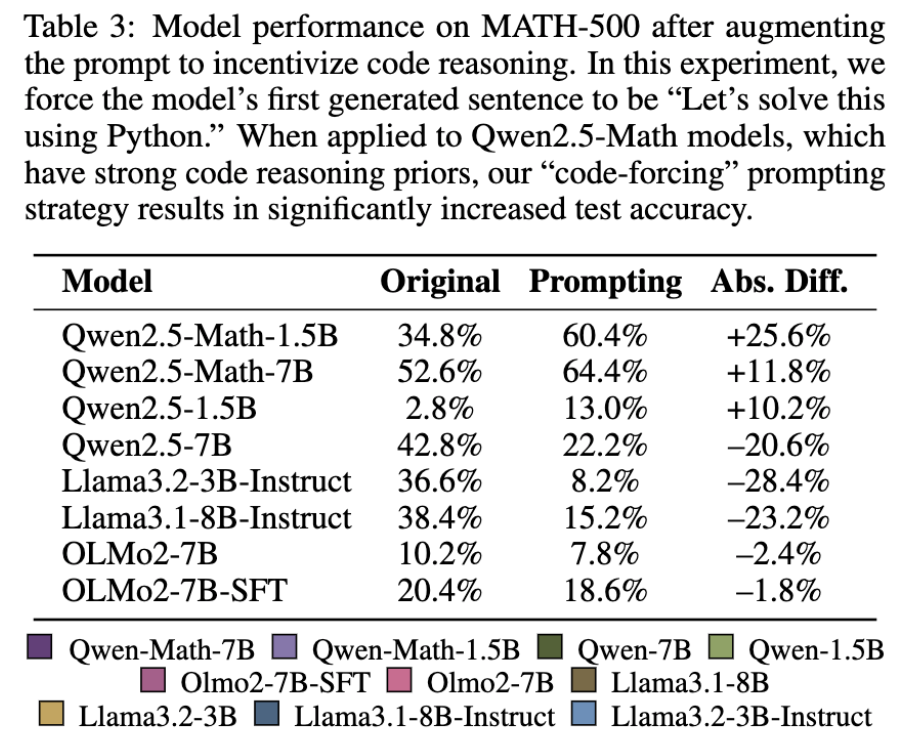
- 엉터리 reward 로 GRPO 학습해도 성능이 나아지는 경우가 있음 (특히 Qwen2.5)
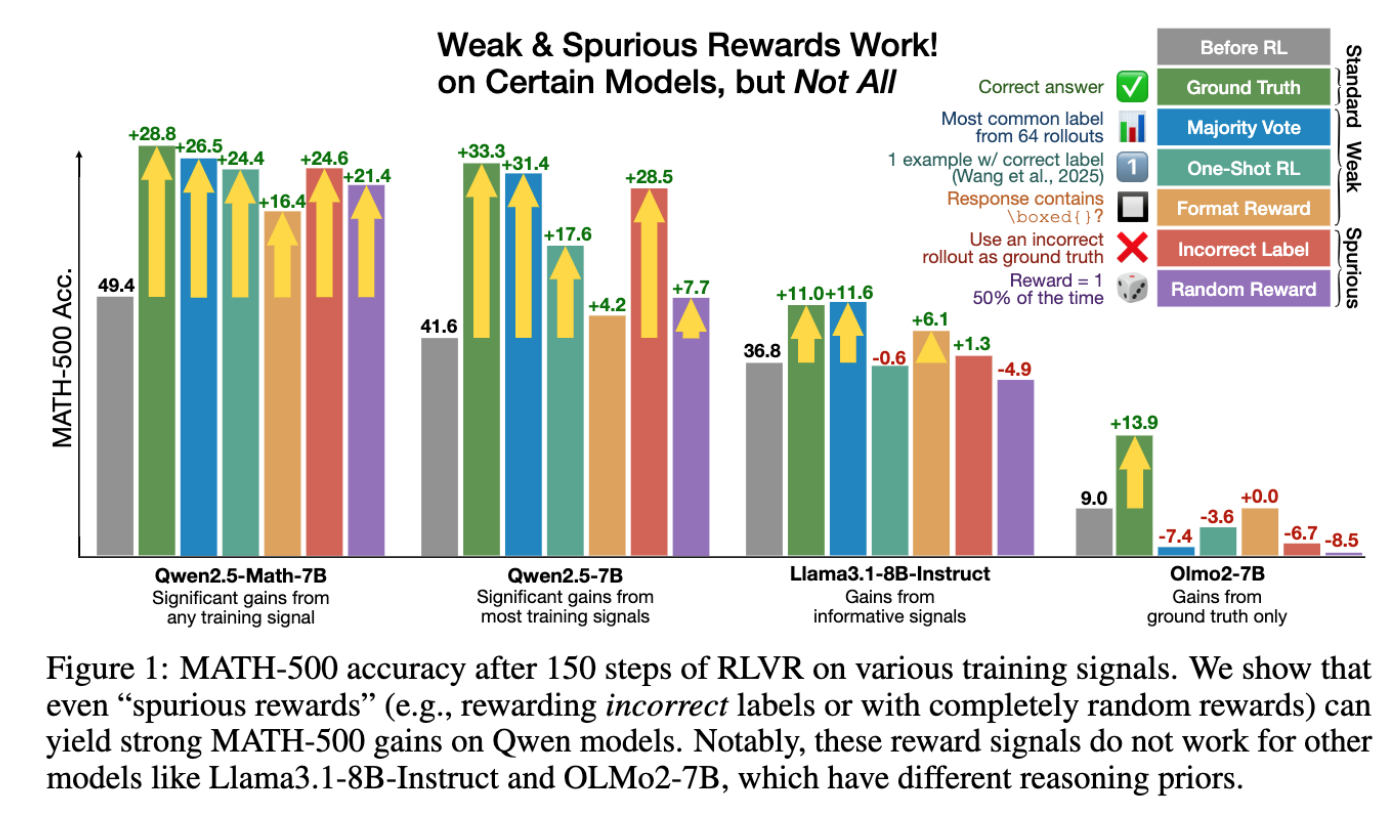
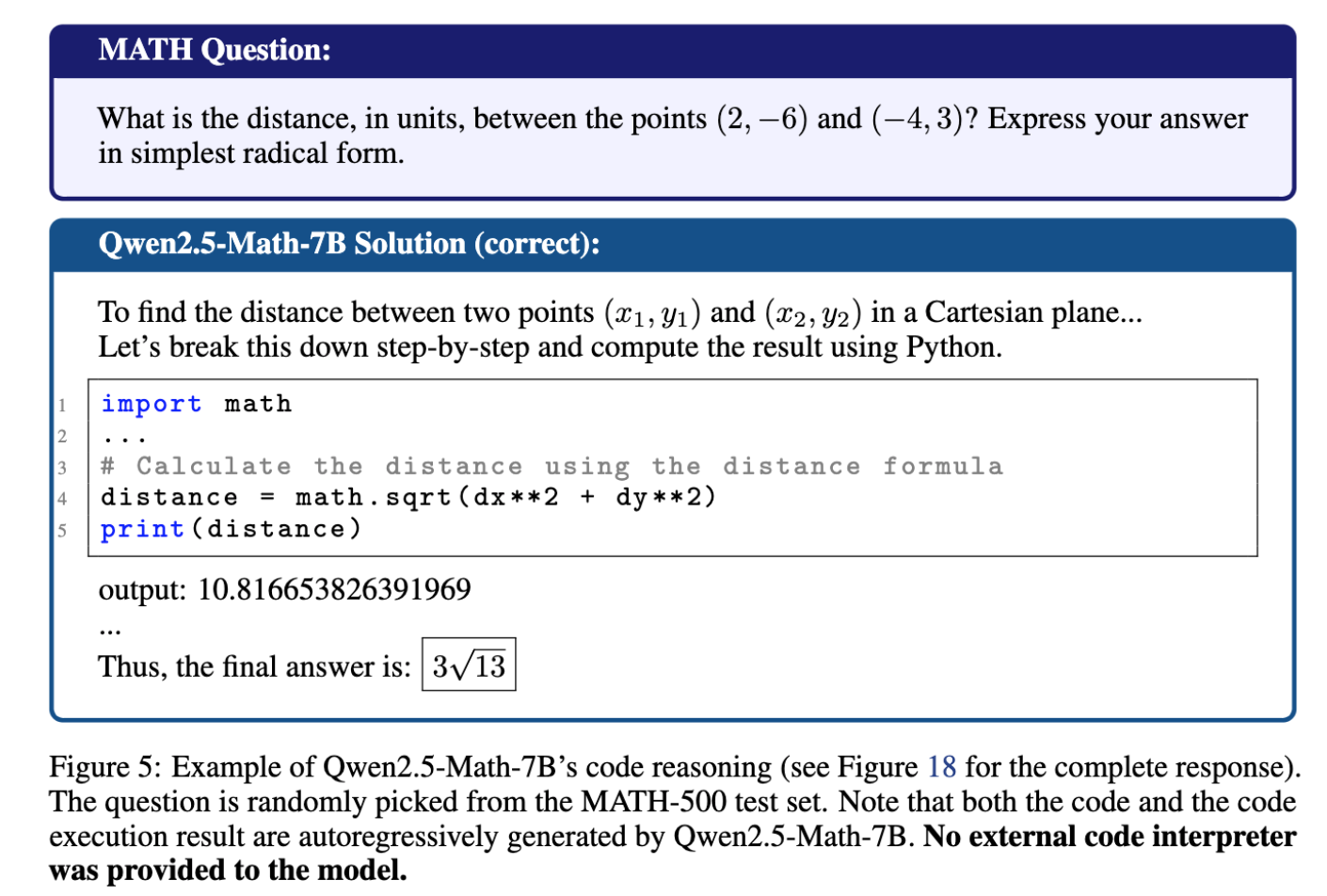
- Qwen2.5-Math-7B 의 경우, 수학 문제를 code 로 푸는 경향성이 있음 (~65%)
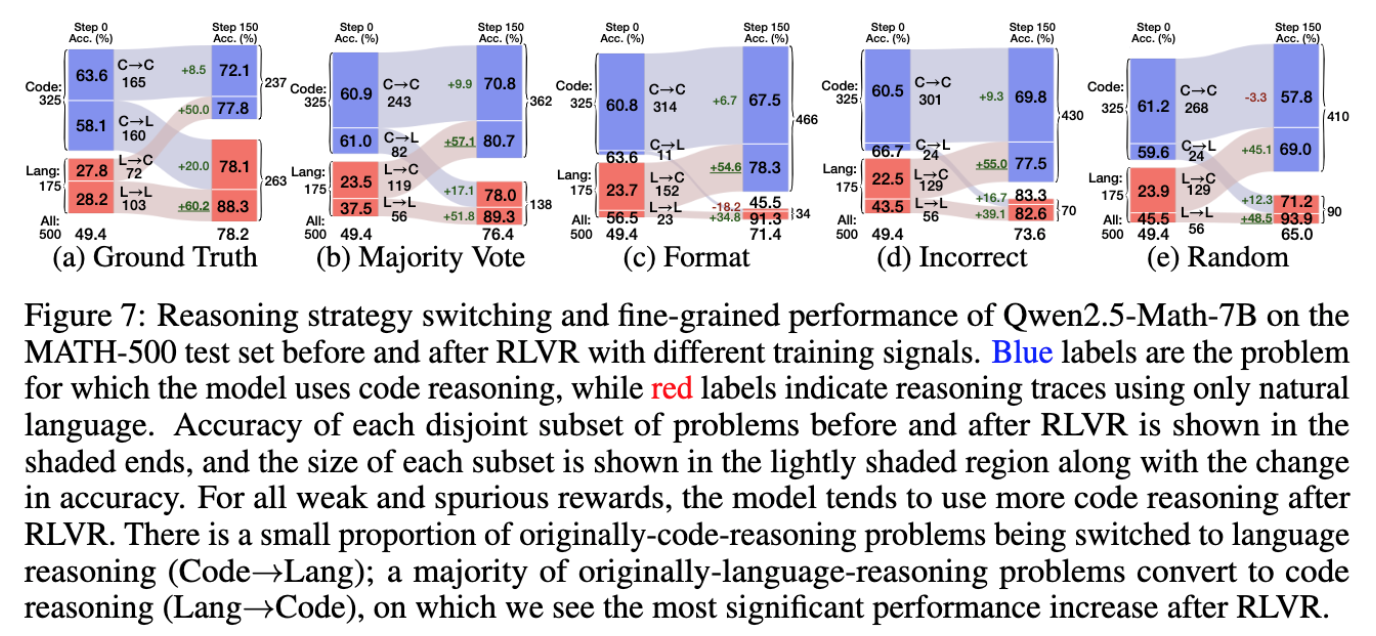
- 풀이 방법이 language 에서 code 로 전환하여 정확도가 높아지는 경우가 많아짐
- Qwen2.5-Math 에게 prompt 를 통해 code 로 수학 문제를 풀라고 하면 성능이 더 좋음