(논문 요약) QWENLONG-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning (Paper)
핵심 내용
- Long-context Document VQA: input + long context -> answer
- Progressive context scaling: initial input length 를 점점 늘려나감
- Warm-Up Supervised Fine-Tuning: SFT 학습 후, RL 학습
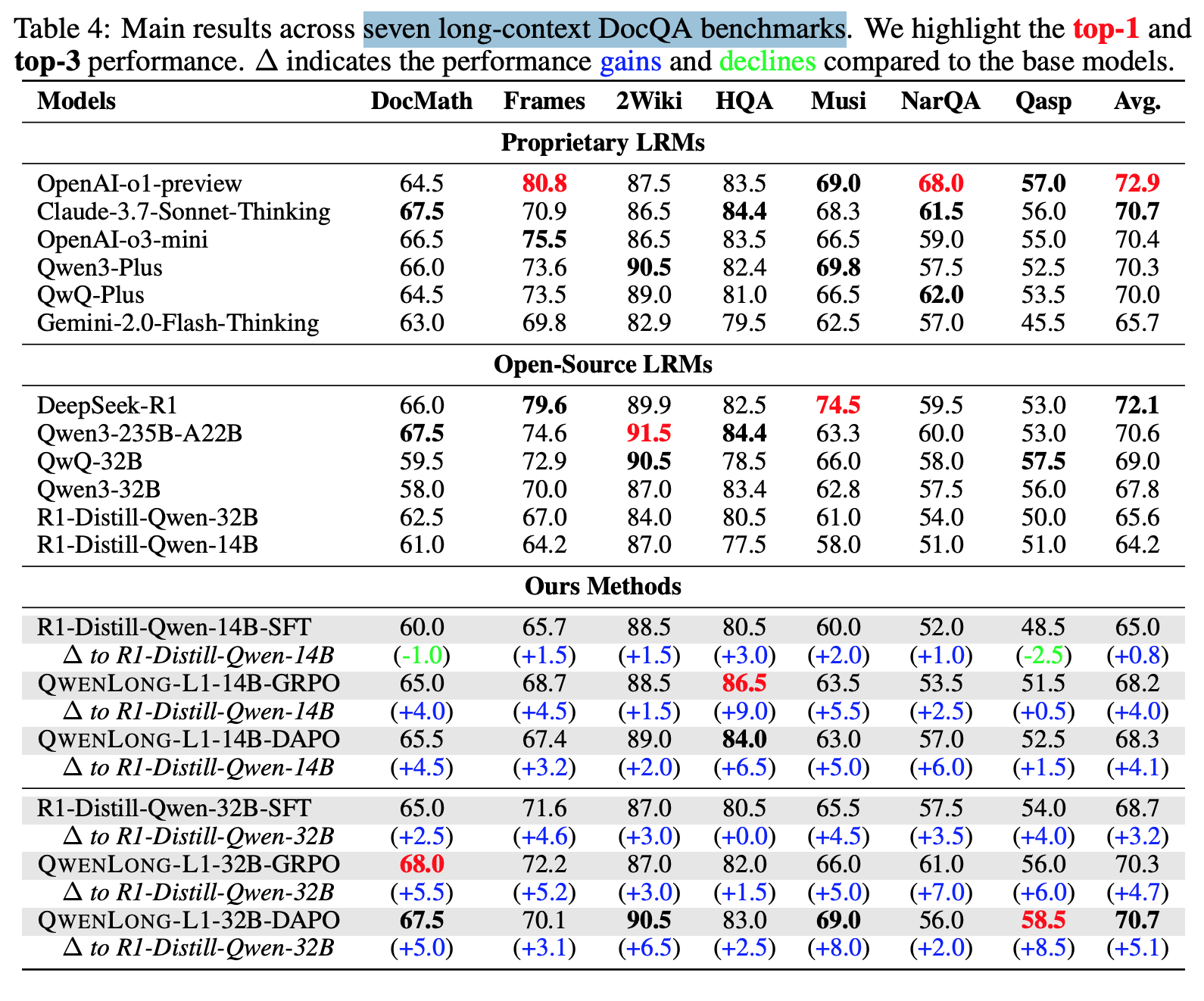
실험
- Long context benchmark 에서 실험