(논문 요약) Qwen2.5-Coder Technical Report (Paper)
핵심 내용
- Qwen2.5 을 이어서 code 데이터로 finetuning
- Code SFT data: Github code, LLM, filtering rules 를 이용하여 생성

- Code SFT data: Github code, LLM, filtering rules 를 이용하여 생성


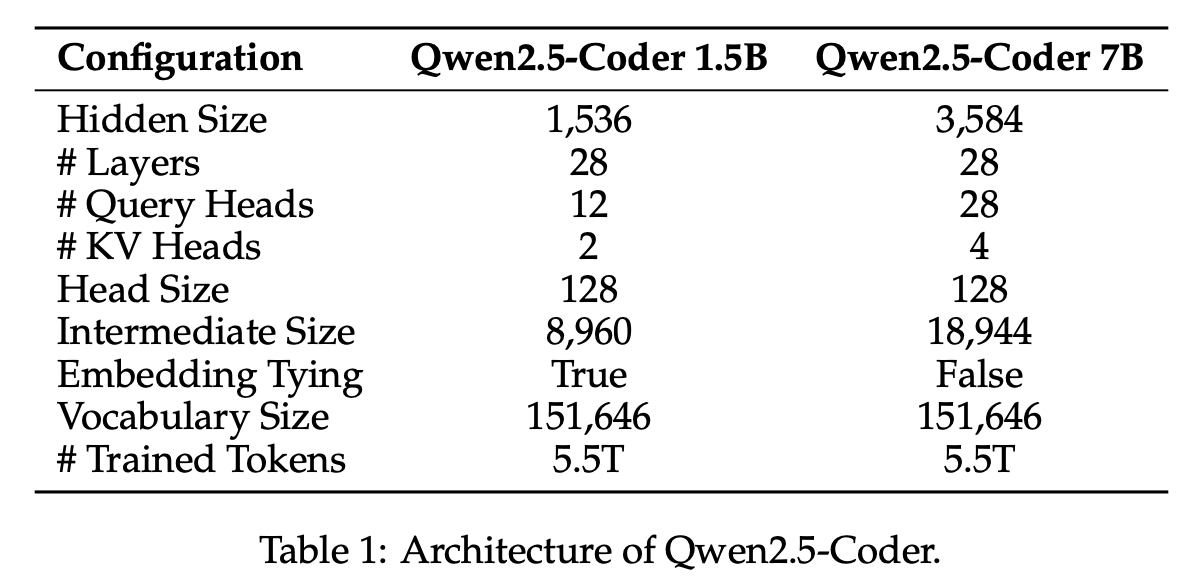
architecture
newly added tokens

Data
- Source code: public repos in GitHub (~Feb 2024), 92 programming languages, rule-based filtered.
- Pull Requests, Commits, Jupyter Notebooks, and Kaggle datasets 도 포함
- Text-Code Grounding Data: high-quality text-code mixed dataset from Common Crawl (code-related documentation, tutorials, blogs)
- Synthetic Data: executable code (generated by CodeQwen1.5)
- Math Data: pre-training corpus from Qwen2.5-Math
- Text Data: high-quality general natural language data from the pre-training corpus of the Qwen2.5
- Source code: public repos in GitHub (~Feb 2024), 92 programming languages, rule-based filtered.
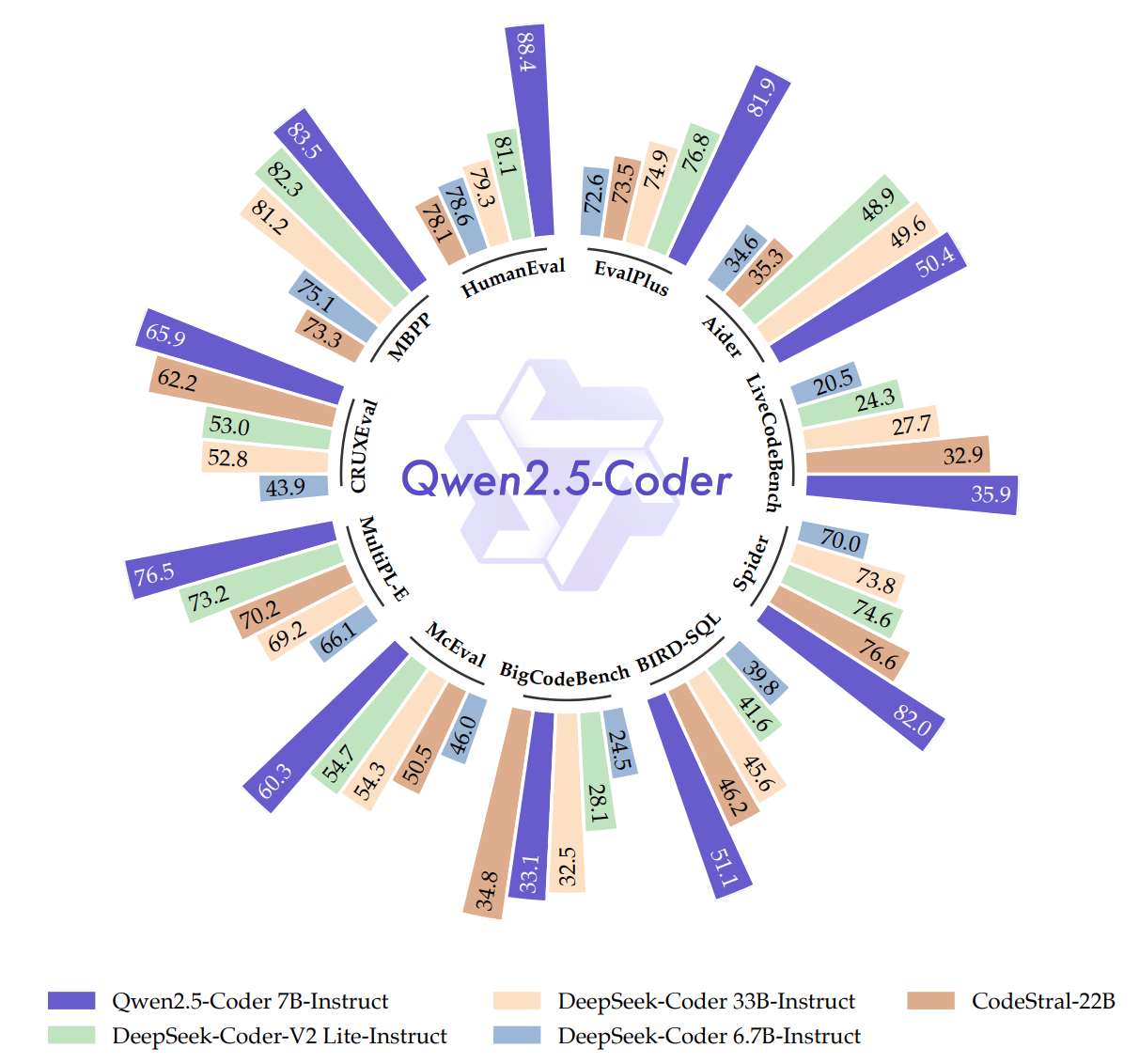
실험 결과