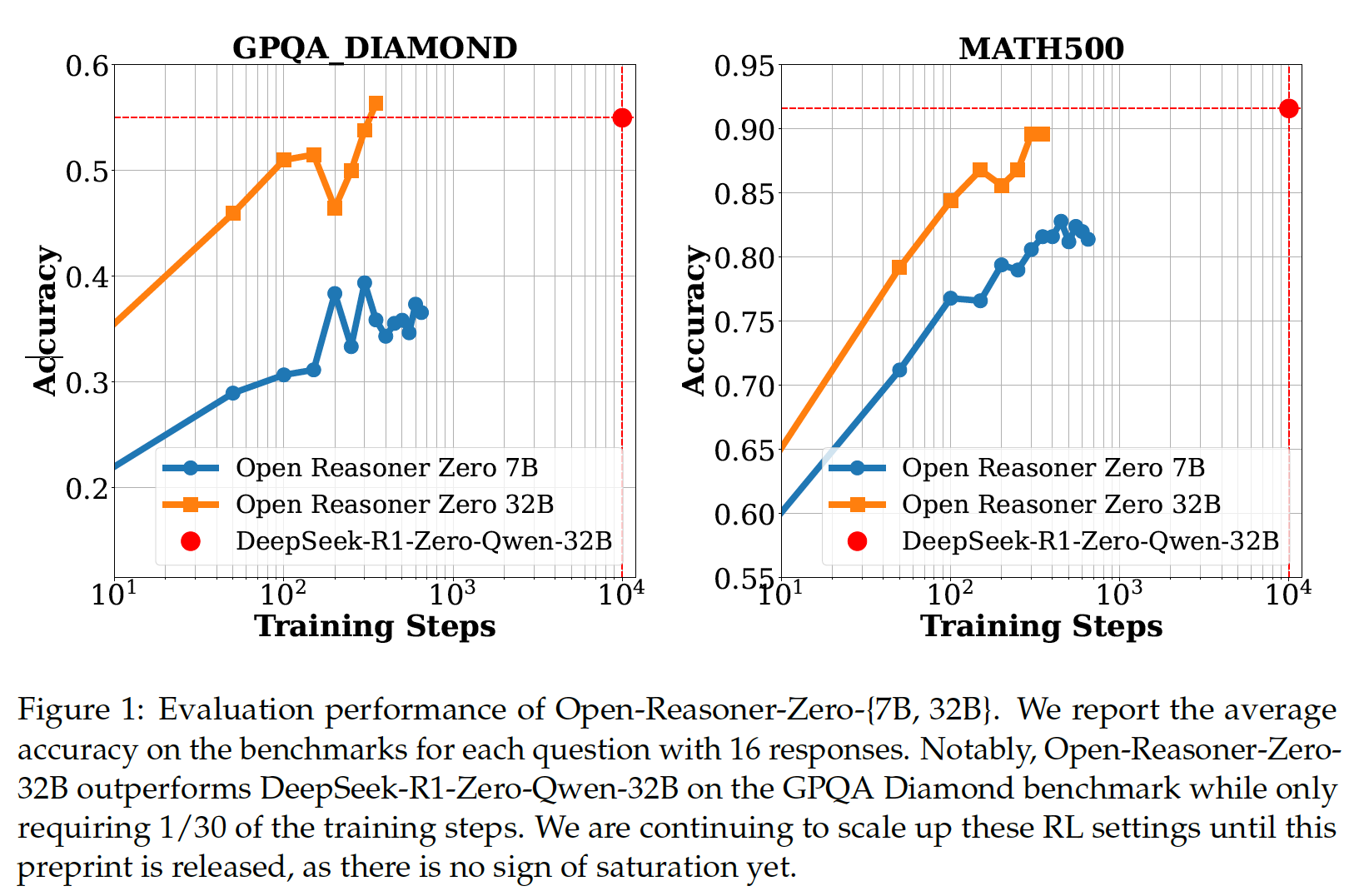
(논문 요약) Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model (Paper)
핵심 내용
최소한의 세팅으로 LRM 학습.
- vanilla PPO
- policy, critic: Qwen-2.5 base models (7B, 32B)
- Generalized Advantage Estimation ($\lambda=1, \gamma=1$)
- $\gamma=1$ 인 경우, value 가 높아지는 next token 생성 가능.
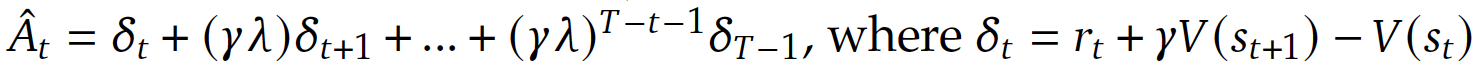
- loss 에 KL-based regularization 없음.
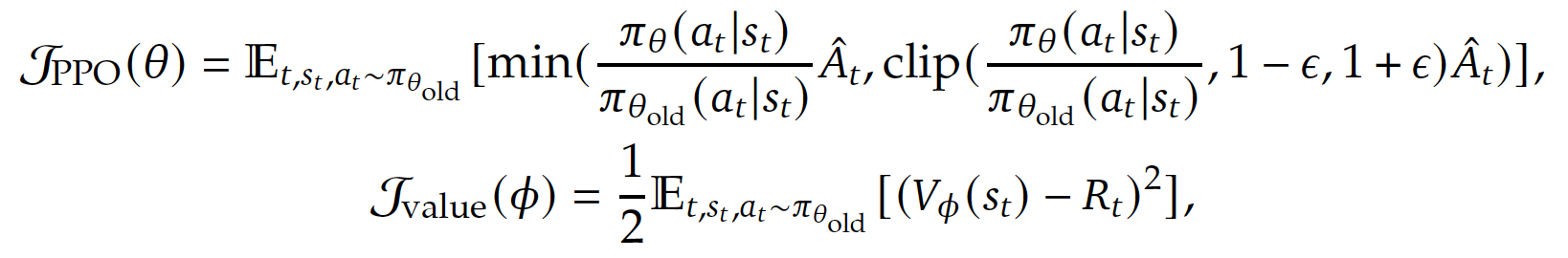
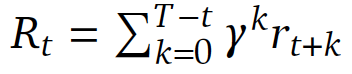
실험 결과