(논문 요약) OPENCODER: THE OPEN COOKBOOK FOR TOP-TIER CODE LARGE LANGUAGE MODELS (Paper)
핵심 내용
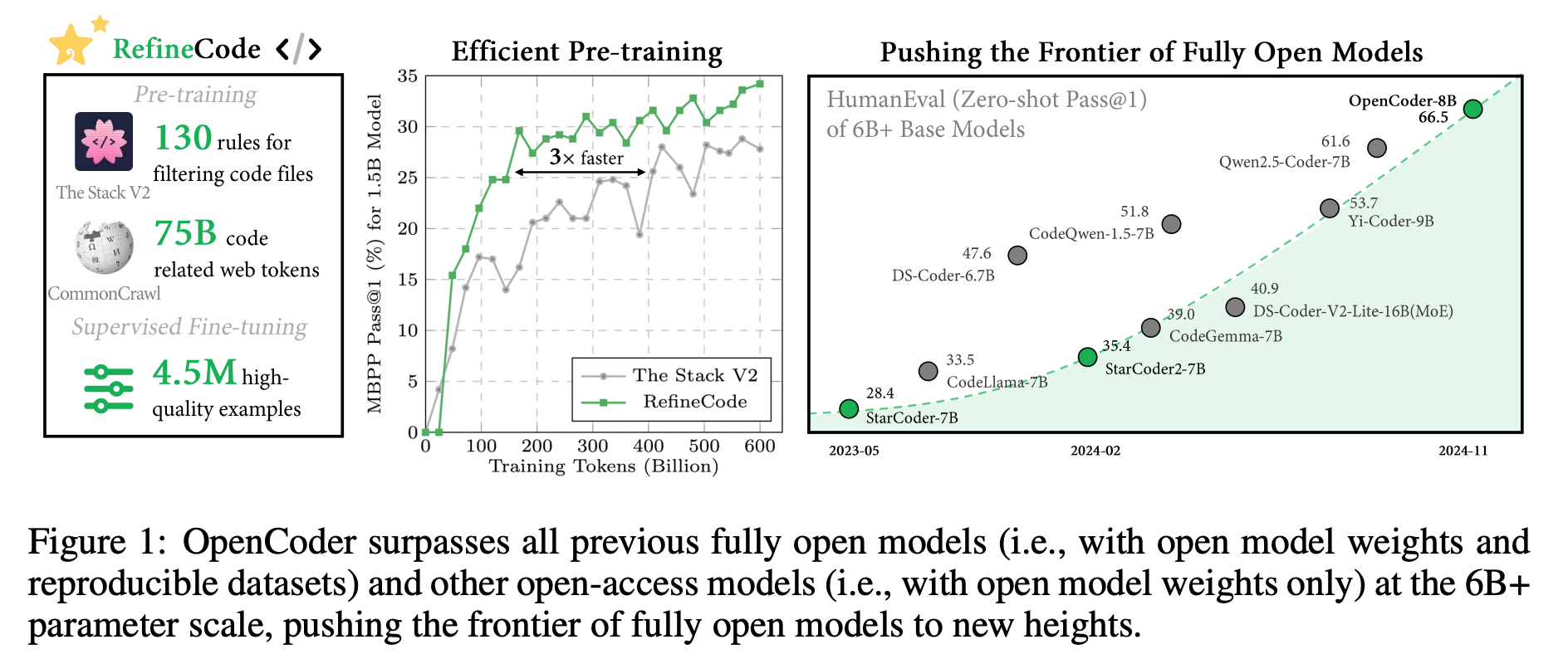
- 1.5B, 8B model 및 학습데이터 (pretrain + finetune) 공개
- RefineCode dataset: GitHub (~2023/11) 및 The Stack v2 에서 추출한 90B tokens (607 programming languages)
- RefineCode dataset: GitHub (~2023/11) 및 The Stack v2 에서 추출한 90B tokens (607 programming languages)
동급 code-LLM 과의 성능 비교

- 데이터 정제 과정
- preprocess: file-level SHA256 로 exact deduplication (star 많고 최신 repo 유지), 5-gram pieces + 2048 MinHash functions 로 fuzzy deduplication
- transformation: Copyright, Personally Identifiable Information 삭제.
- filtering: file-size, #lines, #variables, average function length 및 언어의 특성을 고려하여 low quality data 제거.
- data sampling: downsample popular data (Java: 409GB -> 200GB, HTML: 213GB -> 64GB)
Code-Bert 로 뽑은 feature 를 뿌리면 quality 낮은 데이터는 산개해있음
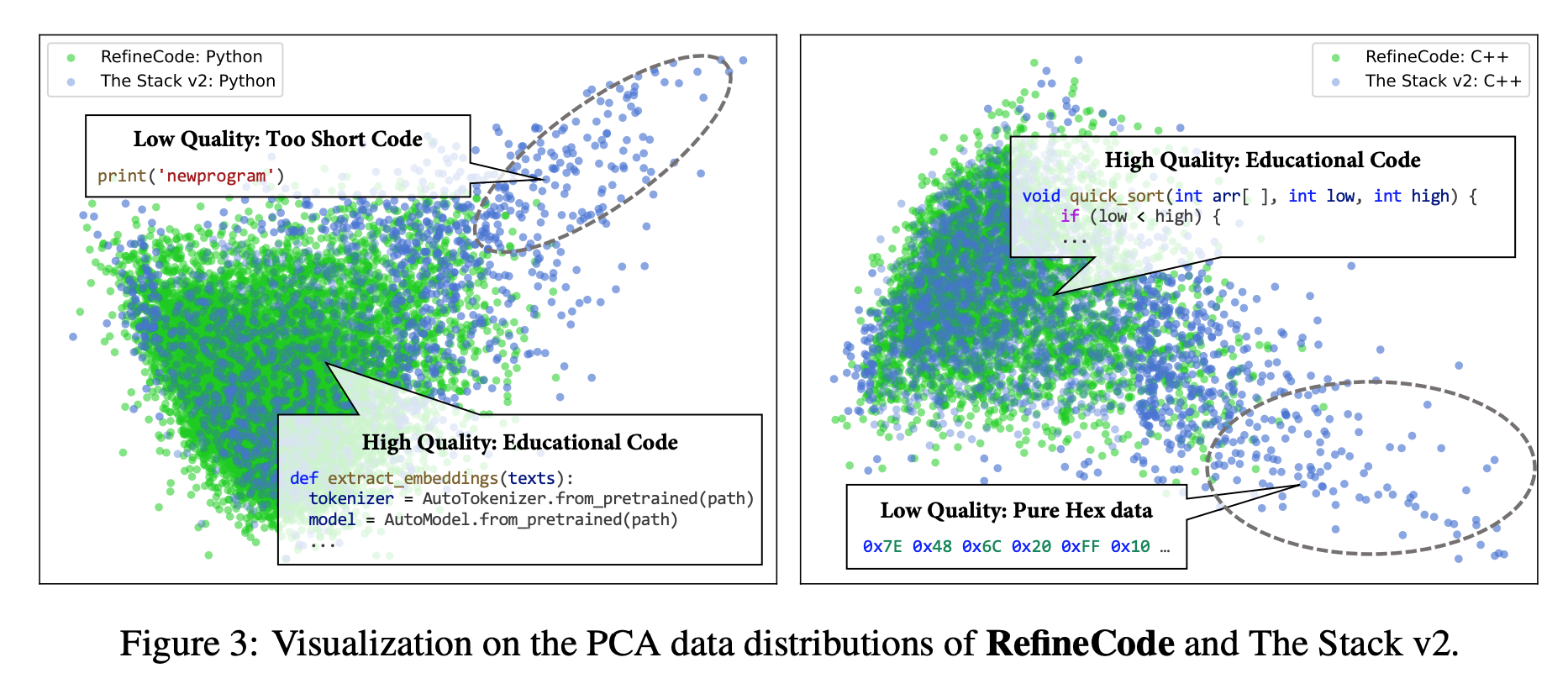
데이터 속성

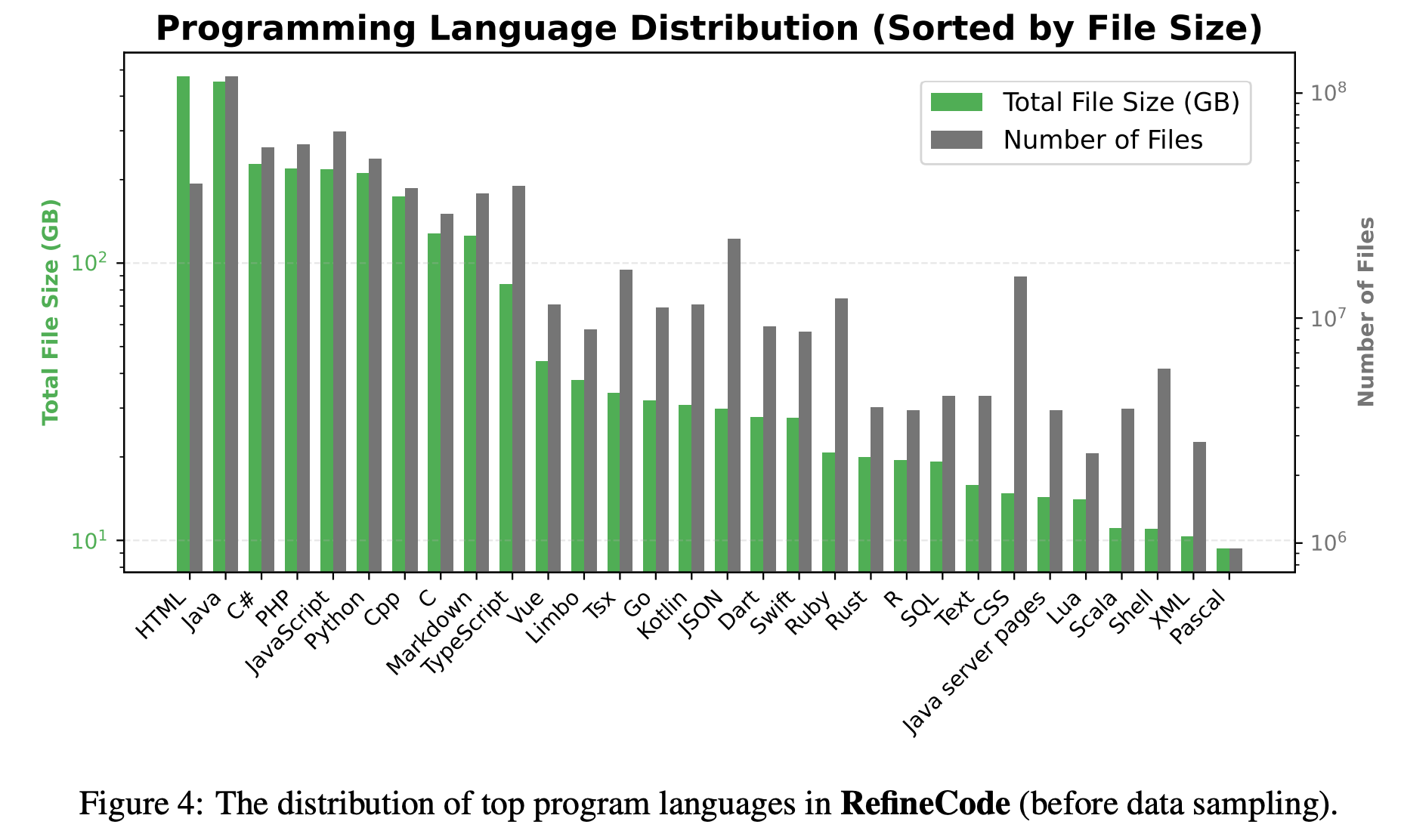
- 기타 사항
- 큰 LLM 을 활용하여 Instruction data 생성
- Two-Stage instruction tuning
- computer science 지식 관련 데이터 학습
- high quality code 데이터 학습