(논문 요약) Large Language Monkeys: Scaling Inference Compute with Repeated Sampling (Paper)
핵심 내용
- output 을 다양하게 생성해서, rule-based verifier 로 검증
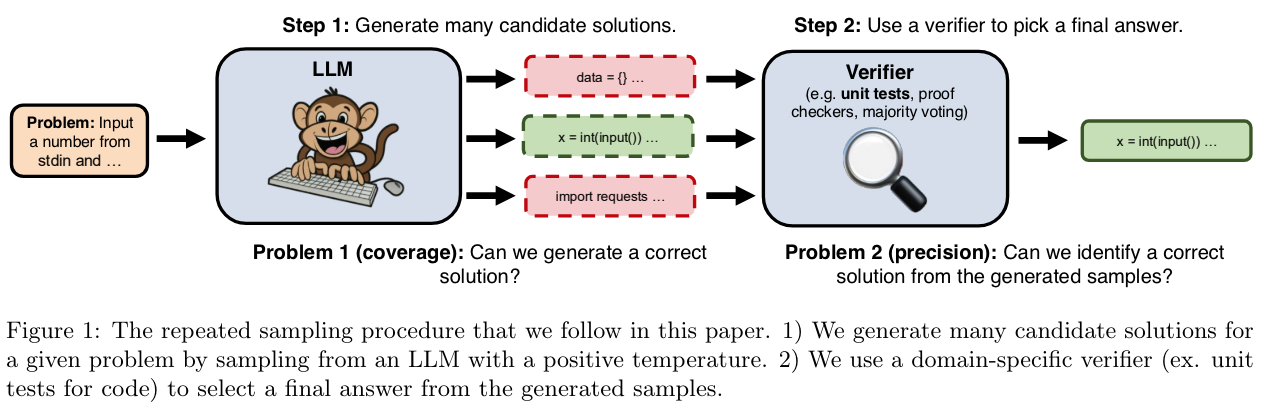
- output 개수에 따른 성능 향상 추이 실험적 관찰
- 실험 데이터
- GSM8K: 초등학교 수학 문제
- MATH: GSM8K 보다 어려운 초등학교 수학 문제
- MiniF2F-MATH: Lean4 로 쓰여진 수학 문제
- CodeContests: 코딩 대회 문제
- SWE-bench Lite: 실제 github issue 모음 (issue 해결을 위해 단일 파일을 찾아서 고쳐야함)
- measure: top-K 개 뽑았을때 정답이 포함될 확률 ($N$개 생성)
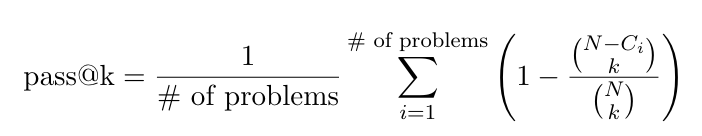
실험 결과
- DeepSeek-Coder-V2-Instruct vs. closed models
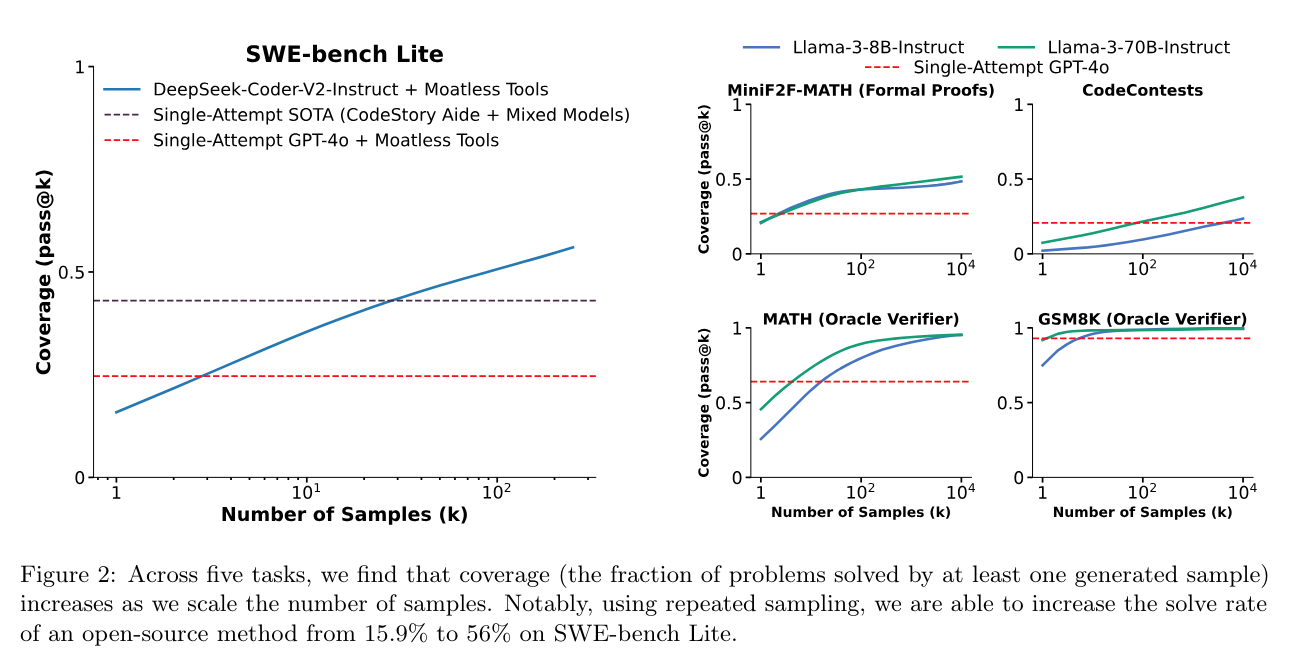
- moatless tool: SWE-bench 를 실행시킬수 있는 github repo
- CodeStory Aide: commercial agent (gpt4o + 3.5 Sonnet)
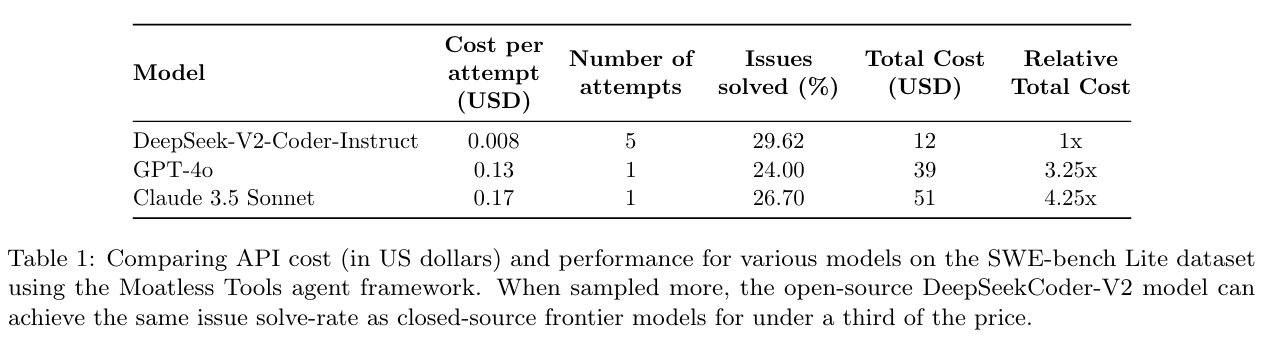
다양한 모델의 실험 결과
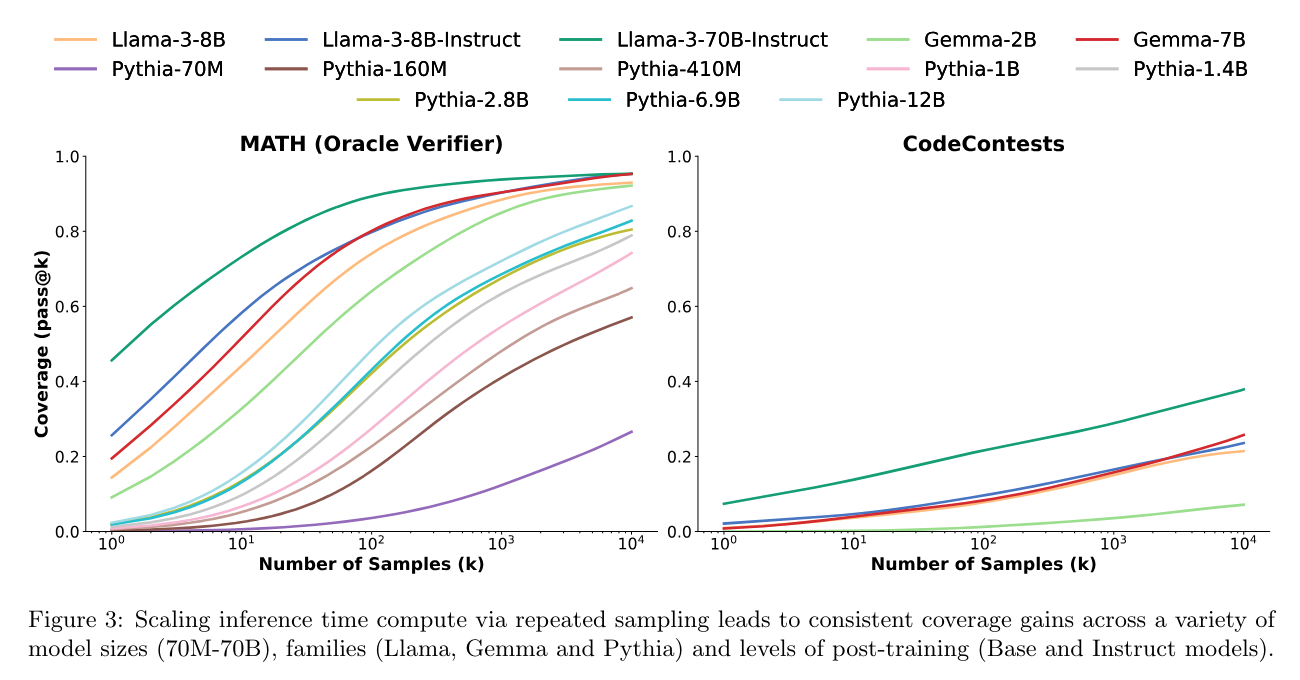
- 모델을 활용한 verification 은 무용지물
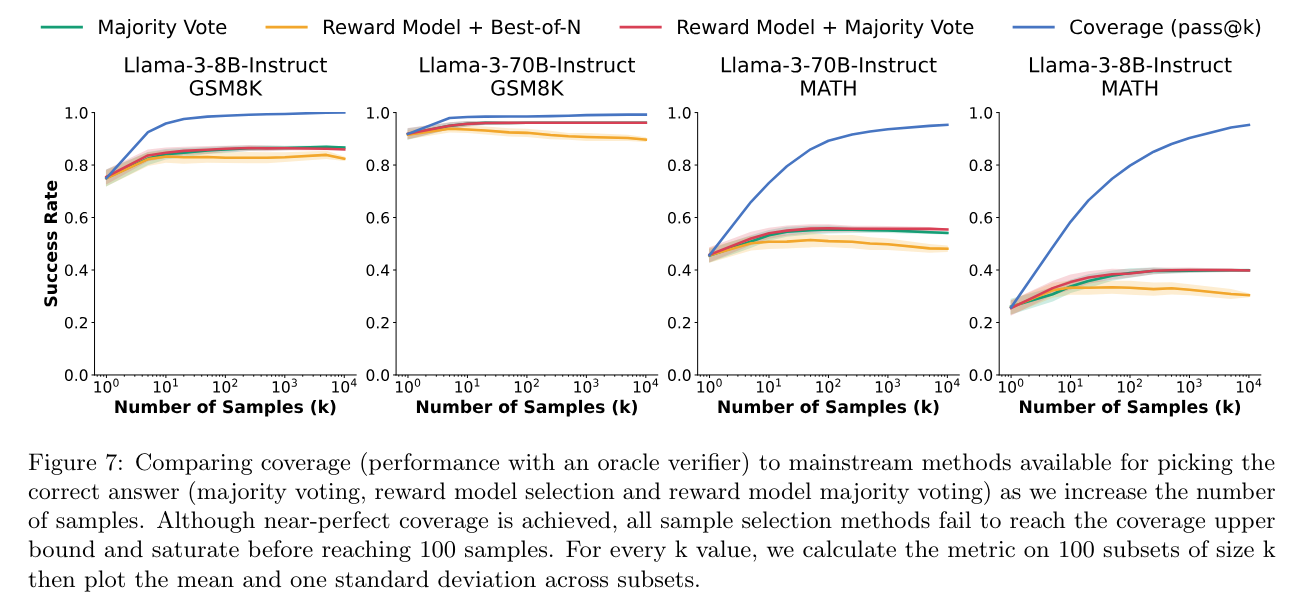
- Majority vote: most common final answer
- Reward Model + Best-of-N: ArmoRM-Llama3-8B-v0.1 reward model (SOTA reasoning on the RewardBench) 로 개별 output 에 score 메긴 뒤, 가장 높은 것 고름
- Reward Model + Majority Vote: ArmoRM-Llama3-8B-v0.1 reward model 로 개별 output 에 score 메긴 뒤, score 에 비례하여 sample
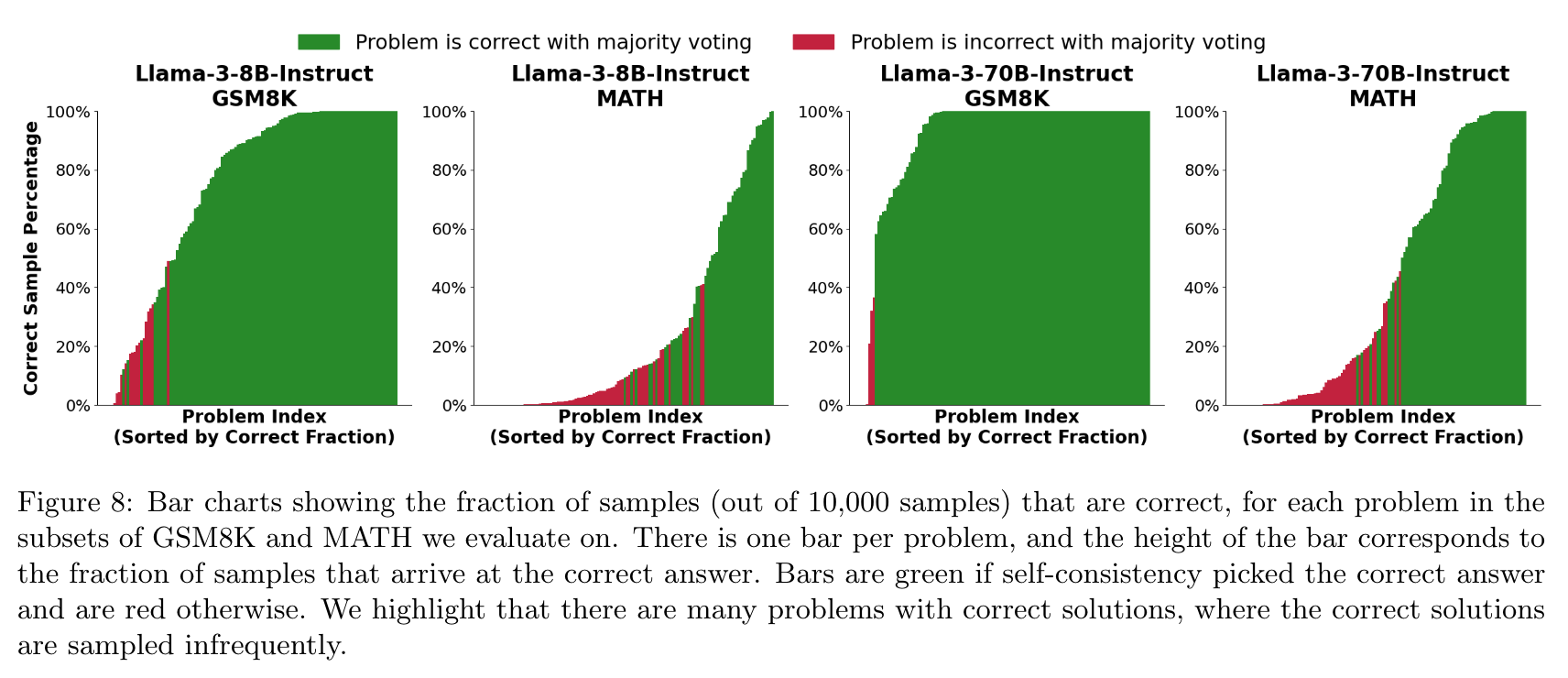
틀리는 케이스 분석: Chain of Thought 단계 하나 하나는 맞는 경우가 많음

- 일부 문제는 정답을 맞출 확률이 극히 낮음 (1만개 output 에서 몇개만 정답을 생성)