(논문 요약) Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs (Paper)
핵심 내용
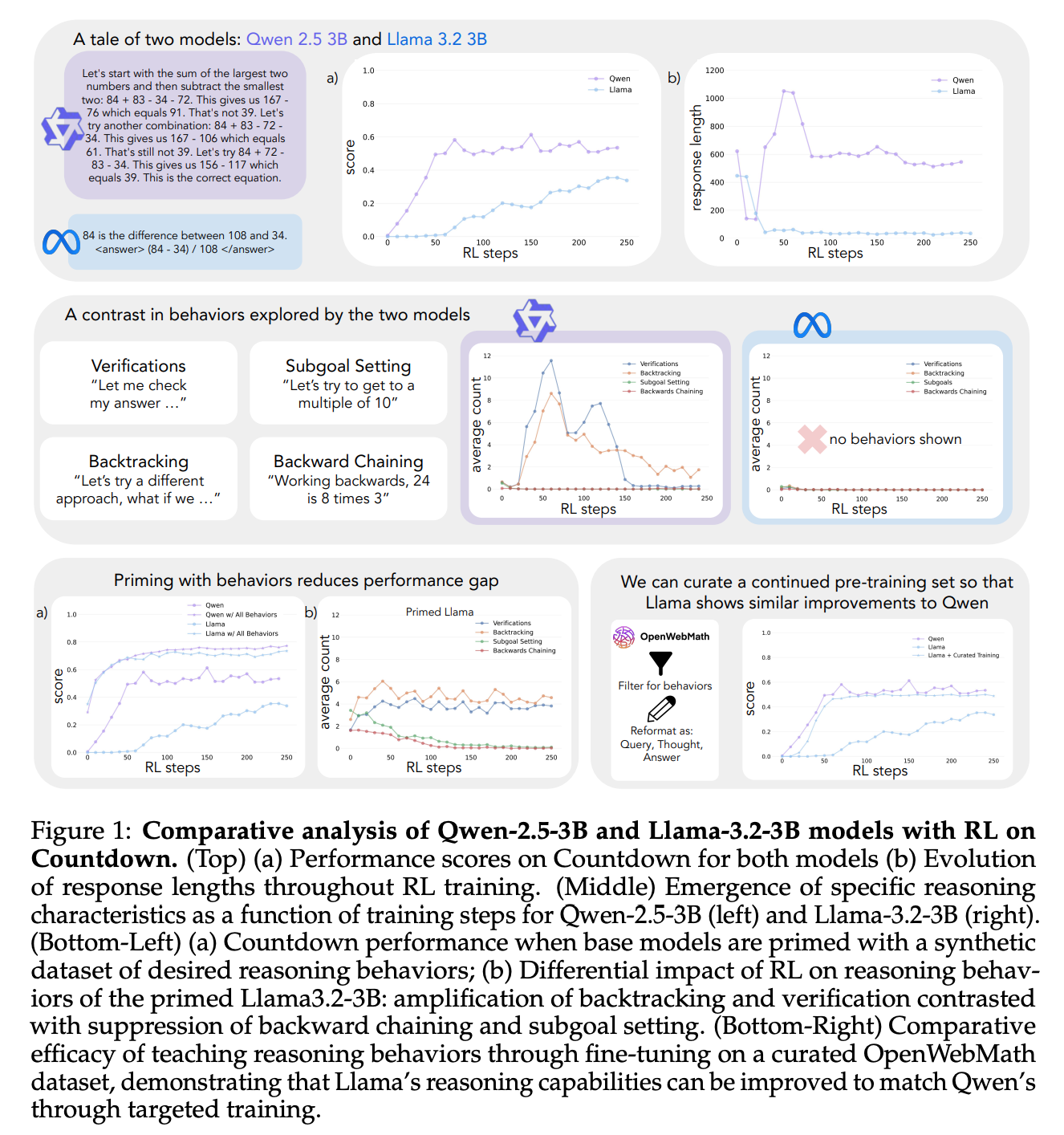
Countdown game: 주어진 숫자들을 조합하여 특정 수를 도출하는 문제
Qwen-2.5-3B 가 Llama-3.2-3B 보다 Countdown game 에서 RL 학습이 더 잘됨.
- Llama-3.2-3B 에 backtracking 을 포함한 trajectory data 로 SFT 진행시, Qwen 만큼 RL 이 효과적이됨.
- trajectory data 는 claude-3-5-sonnet-20241022 사용.
- trajectory data 의 최종 결과가 틀리더라도 상관없음.
- OpenWebMath 데이터를 filtering 하여 continued-pretrain 시, verification, backtracking behavior 가 나타나고, RL 학습시 Qwen 과 비슷하게 효과가 있음.