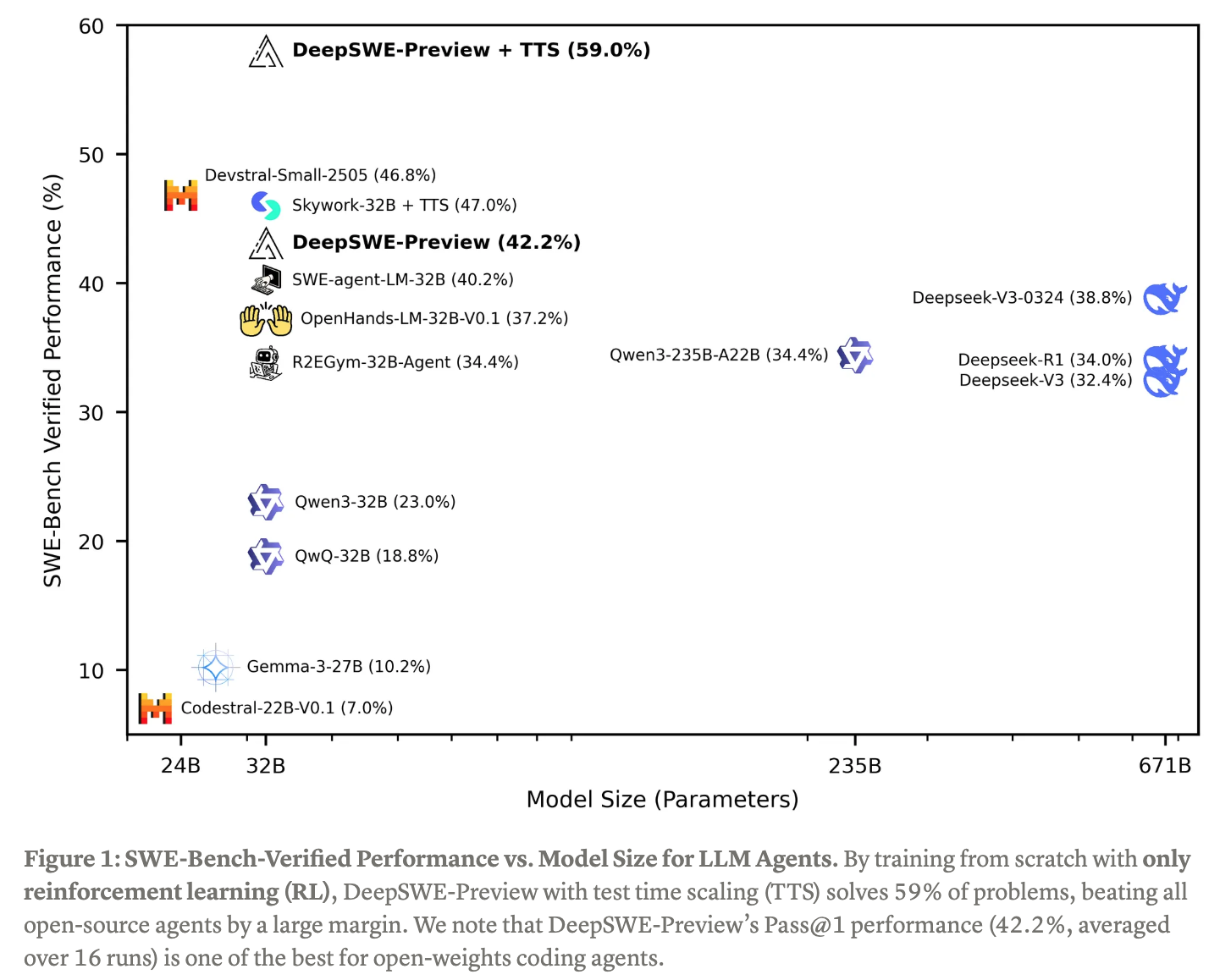
(블로그 요약) DeepSWE: Training a Fully Open-sourced, State-of-the-Art Coding Agent by Scaling RL (huggingface) (blog)
핵심 내용
- Qwen3-32B 에 RL 추가 학습
데이터 셋
- 4.5K problems from a subset of R2E-Gym
- Actions
- Execute Bash
- Search
- File Editor
- Finish/Submit
학습
- 32개 H100 으로 2.5 주 동안 학습
- rLLM library 활용
- Reward 는 맞으면 1, 틀리면 0 (중간 단계 reward 없음)
- context 를 점진적으로 늘려서 학습해나감 (8K->16K->24K)
- GRPO 를 개선하여 학습
- Entropy loss 없앰
- DAPO 에서 처럼 KL loss 없앰
- DAPO 에서 처럼 길이 제한으로 끊어진 경우, loss 에서 제외
- DAPO 에서 처럼 Clip High
- Dr.GRPO 에서 처럼 standard deviation 없앰
- Dr.GRPO 에서 처럼 length normalization (loss 를 context length 로 나눔)
- Leave One Out (Loop/RLOO): Removing one sample for advantage estimation reduces variance for policy gradient without introducing bias.
결과