(논문 요약) DeepSeek-R1 (Github)
핵심 내용
- DeepSeek-R1-Zero: RL 만으로 학습이 되는지 확인하기 위한 실험.
- Group Relative Policy Optimization 로 학습
- 문제 $q$ 에 대해 $G$ 개 output 생성후 PPO
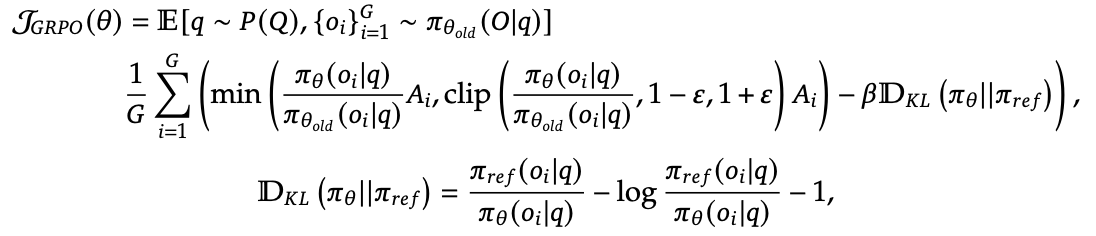
- advantage $A_i=\frac{r_i-mean(r_1,…,r_G)}{std(r_1,…,r_G)}$
- KL estimator: blog
- 문제 $q$ 에 대해 $G$ 개 output 생성후 PPO
- Reward
- Accuracy: 수학은 최종 정답이 맞는지, 코드는 실행 결과 정답과 일치하는지.
- Format: think tag 를 붙이는지.
- Prompt: 하나의 prompt 사용.

- Group Relative Policy Optimization 로 학습
- DeepSeek-R1: SFT 이후에 RL 학습.
- CoT 데이터로 DeepSeek-V3-Base 를 SFT 로 학습.
- Reasoning data
- prompt 를 사람이 curate.
- DeepSeek-V3 모델을 judge 사용하여 맞는 케이스만 남김.
- 600K prompt-answer pairs.
- Non-reasoning data
- DeepSeek-V3 의 SFT 데이터 일부 + DeepSeek-V3 모델로 생성
- 200K prompt-answer pairs.
- Reasoning data
- 이후에 language proportion 을 reward 에 추가하여 (언어를 섞는 현상 줄이기 위함) RL 로 학습.
- CoT 데이터로 DeepSeek-V3-Base 를 SFT 로 학습.
- Distill the reasoning capability from DeepSeek-R1 to small dense models.
- Qwen 및 Llama 의 1.5B, 7B, 8B, 14B, 32B, 70B 모델들을 SFT 로 학습.
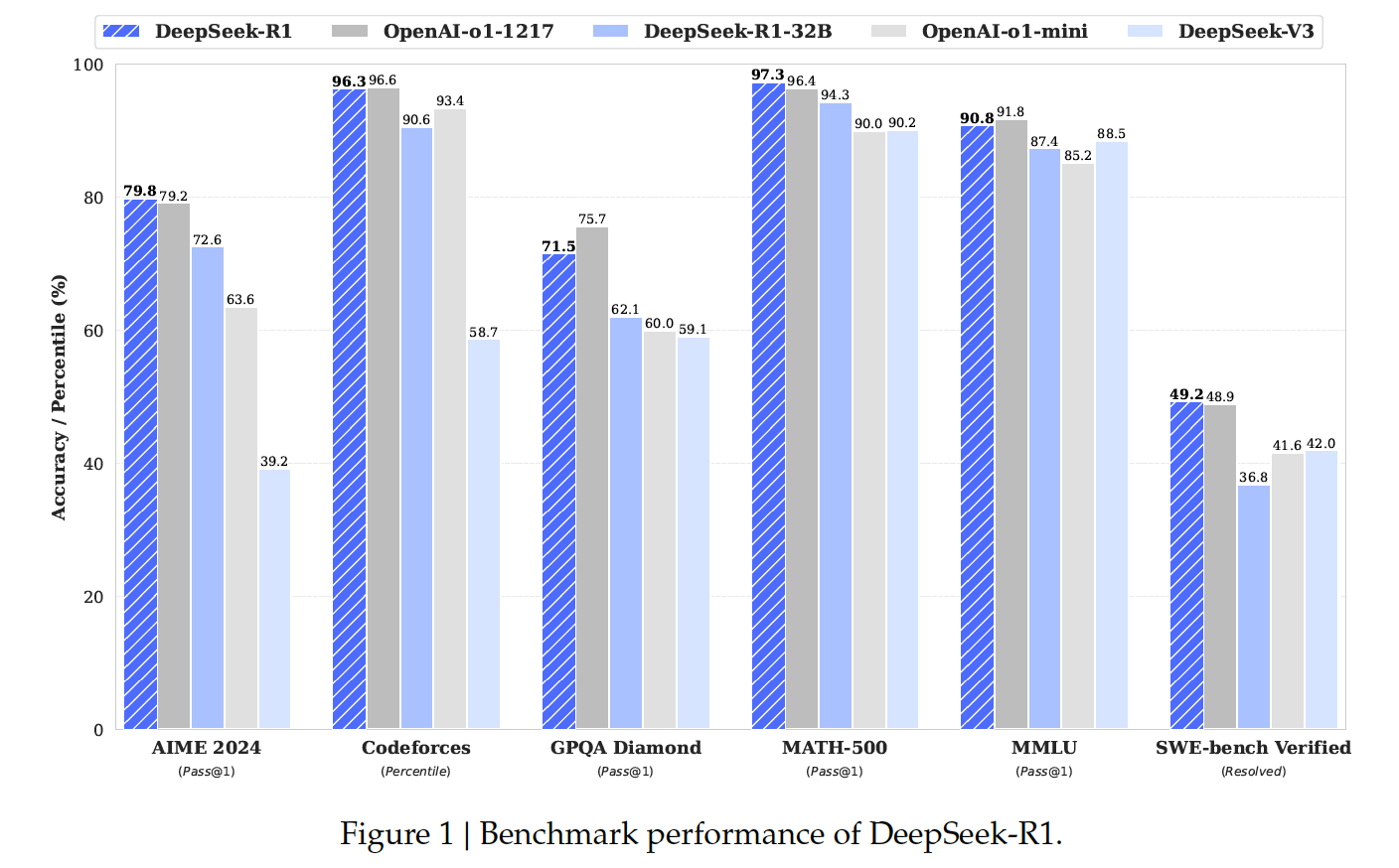
실험 결과