(논문 요약) DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition (paper)
핵심 내용
- Expert-Iteration data
- 못푼 문제중 맞는 것들을 데이터에 추가하면서 SFT
- CoT data
- DeepSeek-V3 로 sketch 를 한 뒤, LEAN 코드로 subgoals 로 나눔
- 각 subgoal 을 7B prover 모델로 해결
- 모두 해결된 경우, LEAN code 를 sketch 에 치환하여 데이터로 활용

- 학습
- SFT: DeepSeek-V3-Base-671B 를 Expert-Iteration data + CoT data 로 학습
- SFT 이후, GRPO 로 학습
실험 결과
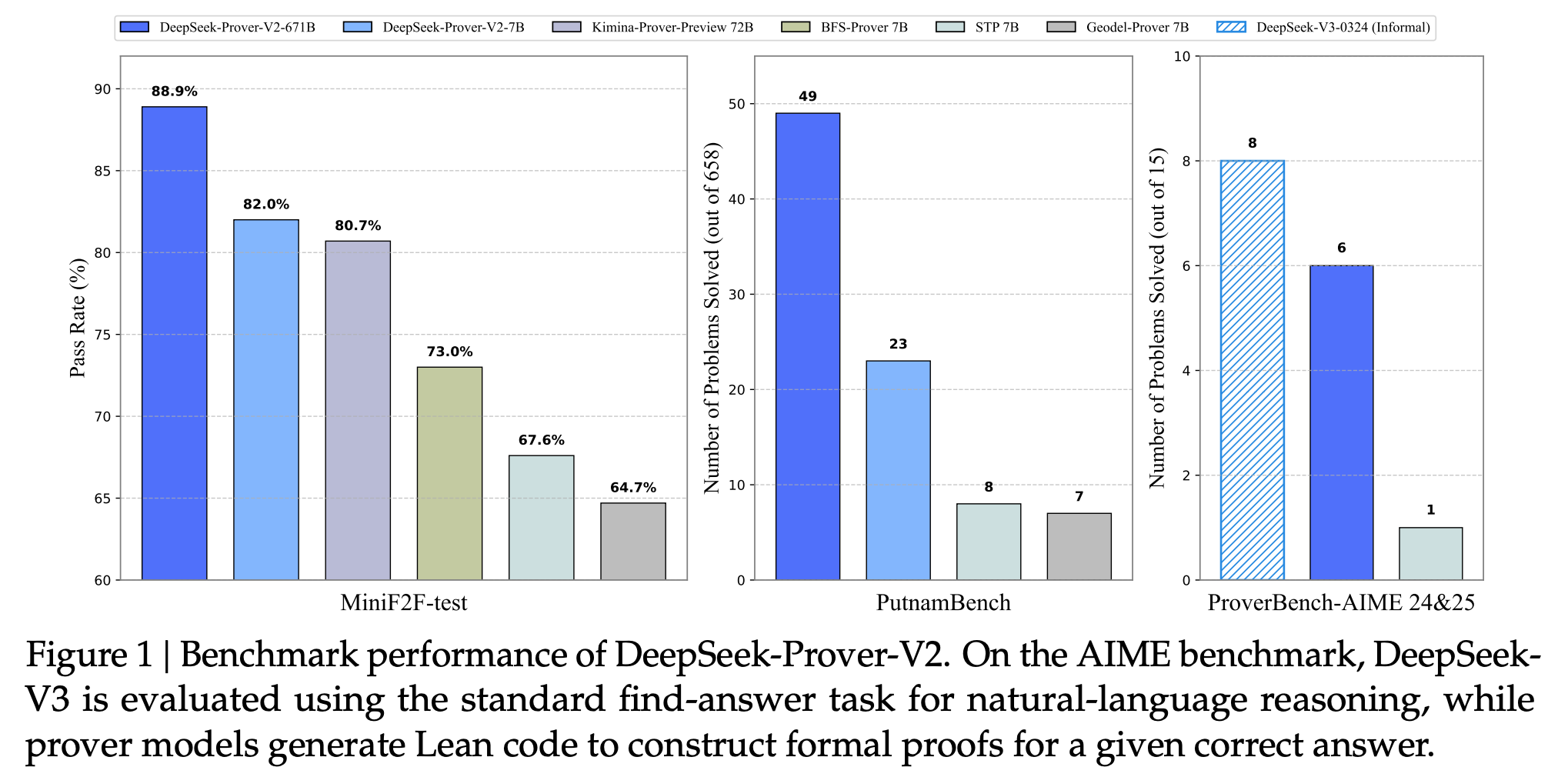
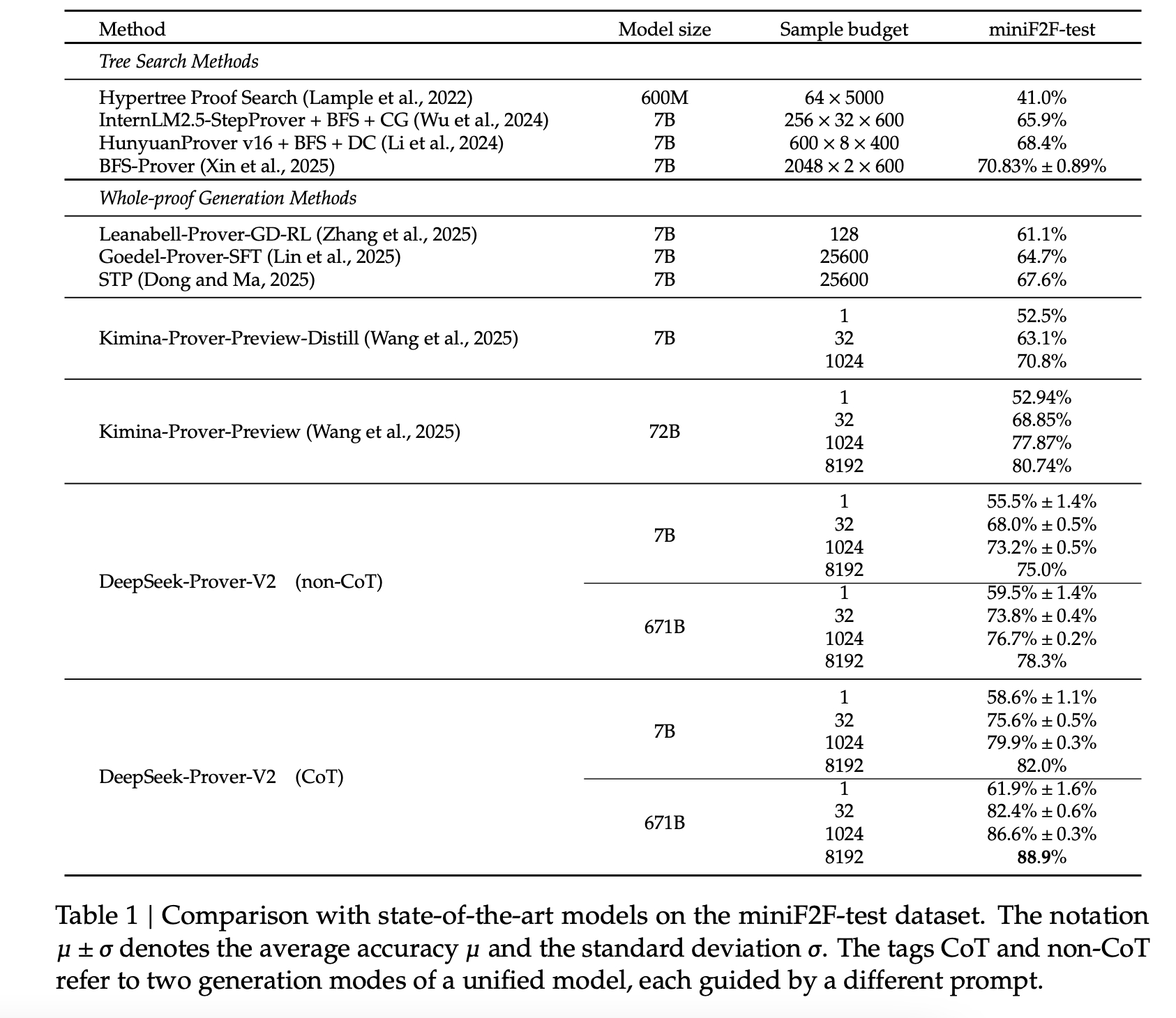
- Model size 와 Sample budget 에 따른 miniF2F-test 비교