(논문 요약) Training Large Language Models to Reason in a Continuous Latent Space (Paper)
핵심 내용
Input embedding 을 생성 (continuous space)
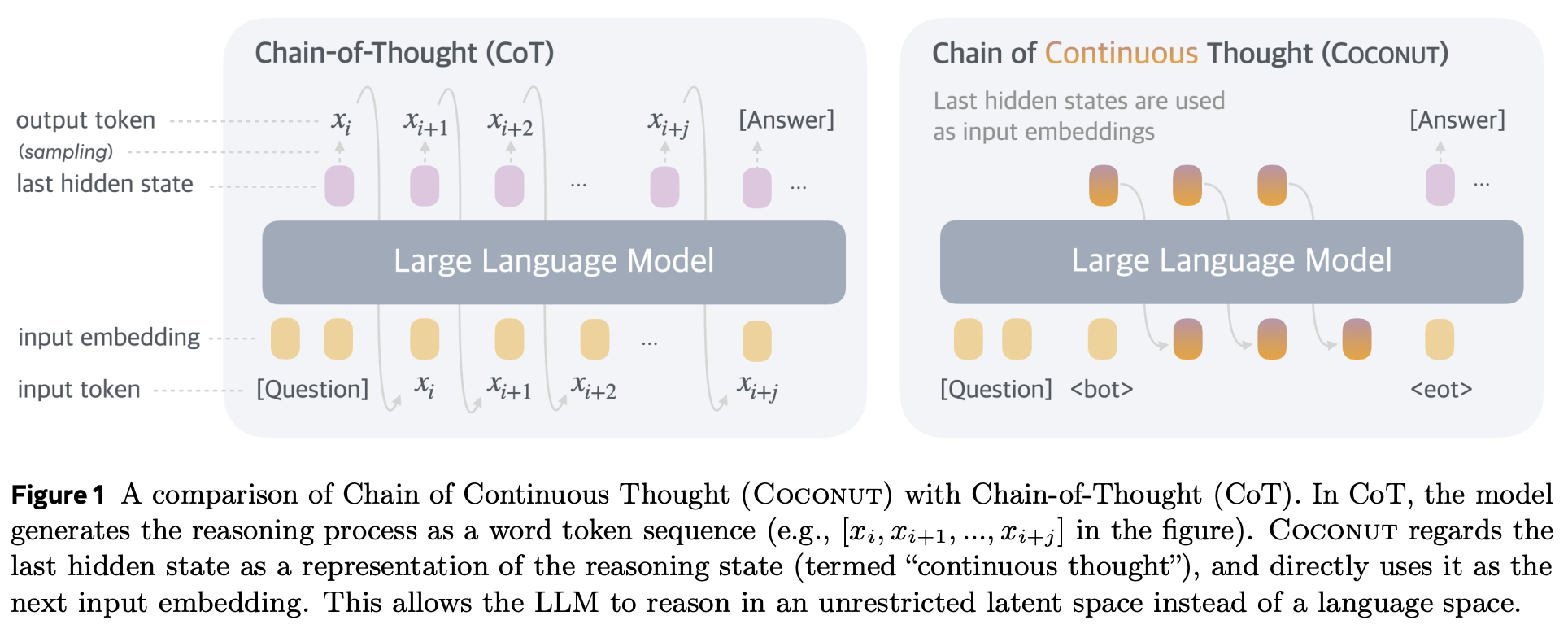
학습시 step 한 단계를 $c$ 단계의 continuous token(s) 으로 대체

실험 결과
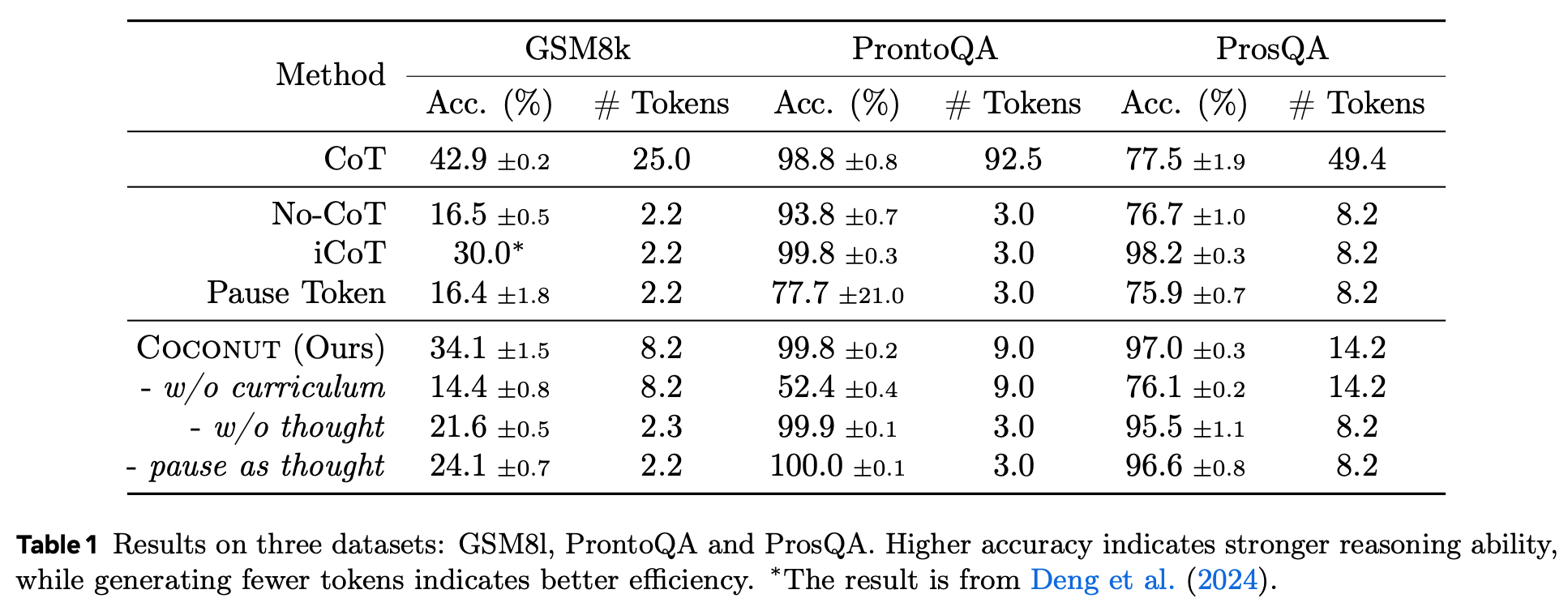
- iCoT: internalized CoT
- Pause token: special
tokens inserted between the question and answer - w/o curriculum: directly train questions and answers in the final stage
- w/o thought: no continuous latent thought generated
- pause as thought:
tokens to replace the continuous thoughts