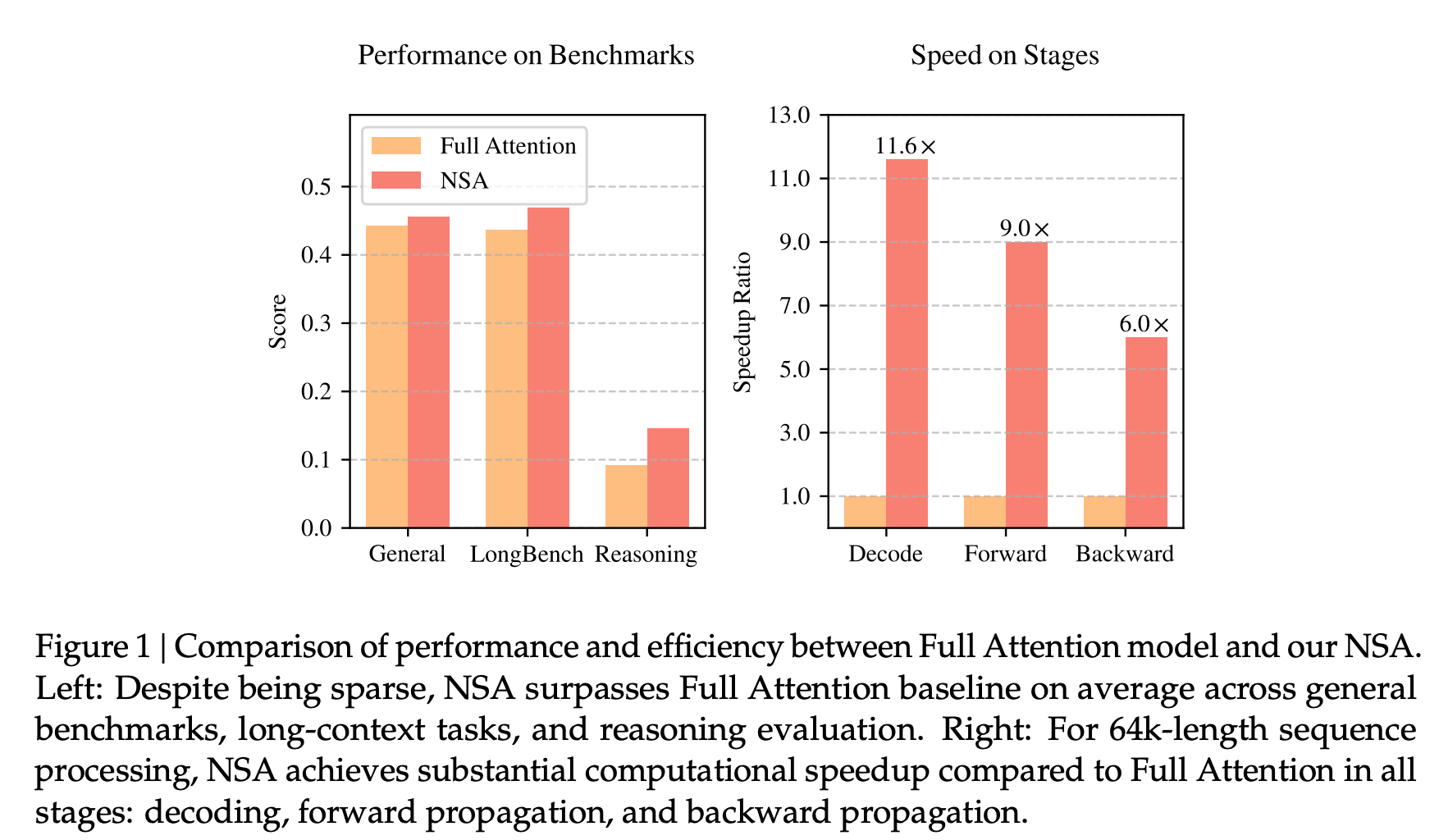
(논문 요약) Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention (Paper)
핵심 내용
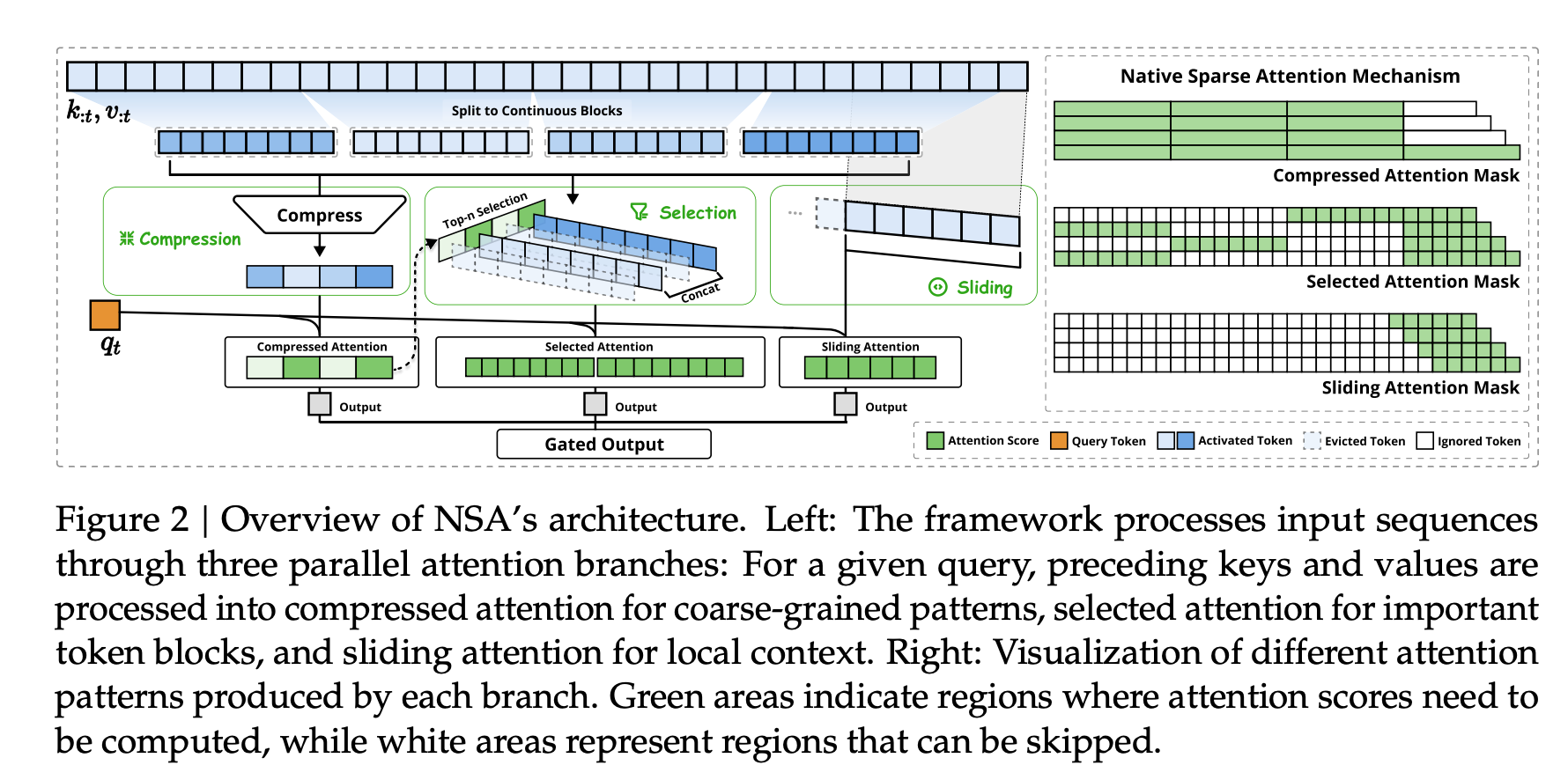
- compression: key, value 를 압축시킴 (stride 를 두고, 길이를 $L\rightarrow 1$)
- selection: key, query 의 dot product 가 높은 key, value 가져옴 (GQA, MQA 의 경우 query head 들 전부 더함)
- sliding attention: last length $L$
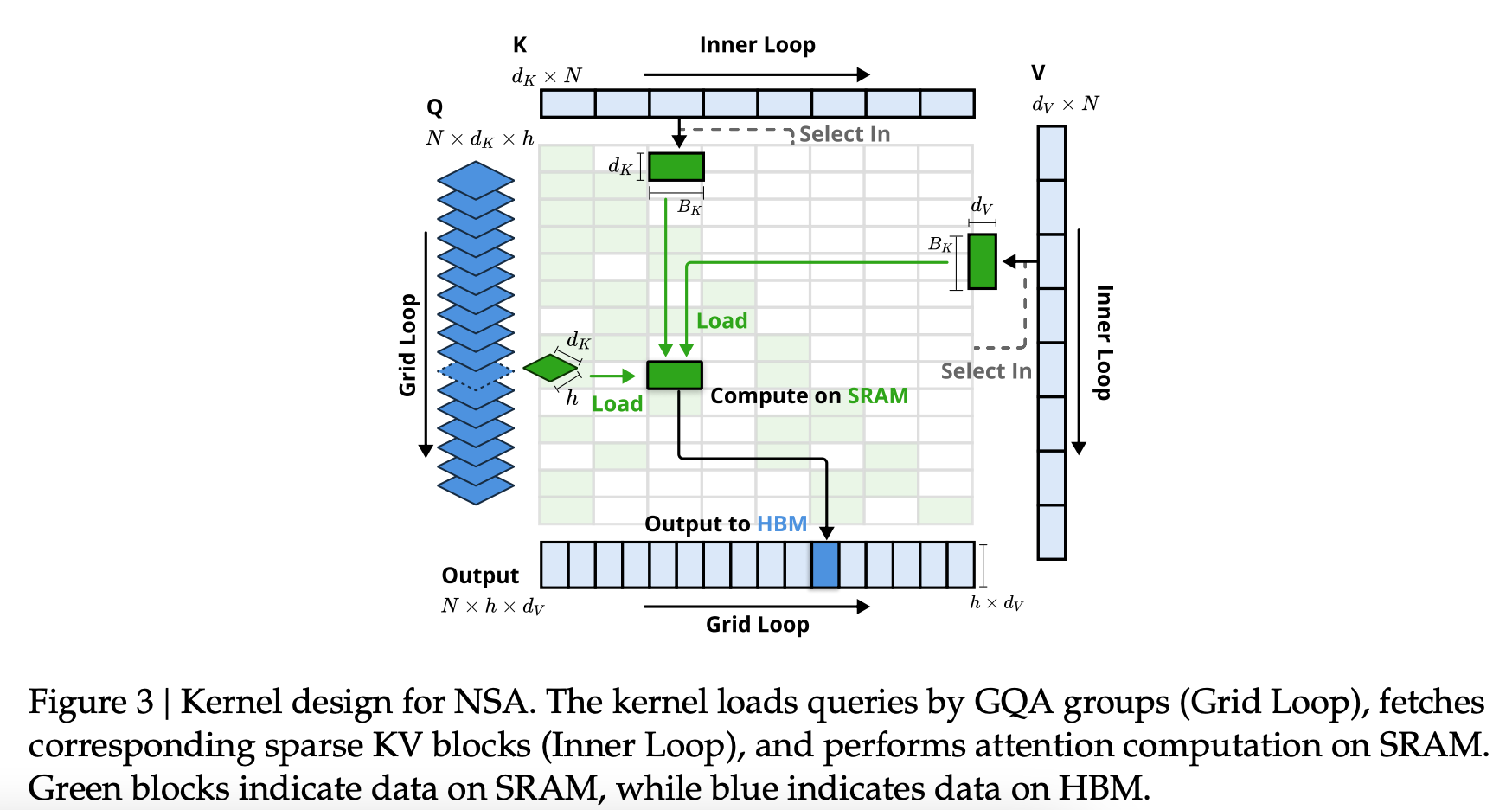
- load all head quries
- inner loop 에서 key, value 로딩
실험