(논문 요약) Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention (Paper)
핵심 내용
- 컨셉:
- 이전 Key, Value 들을 compressive memory 형태로 유지.
- 현재의 Query 를 통해서 원하는 부분 추출.
- 현재의 Multi-Head-Attention 과 interpolation (head 당 interpolation weight 학습).
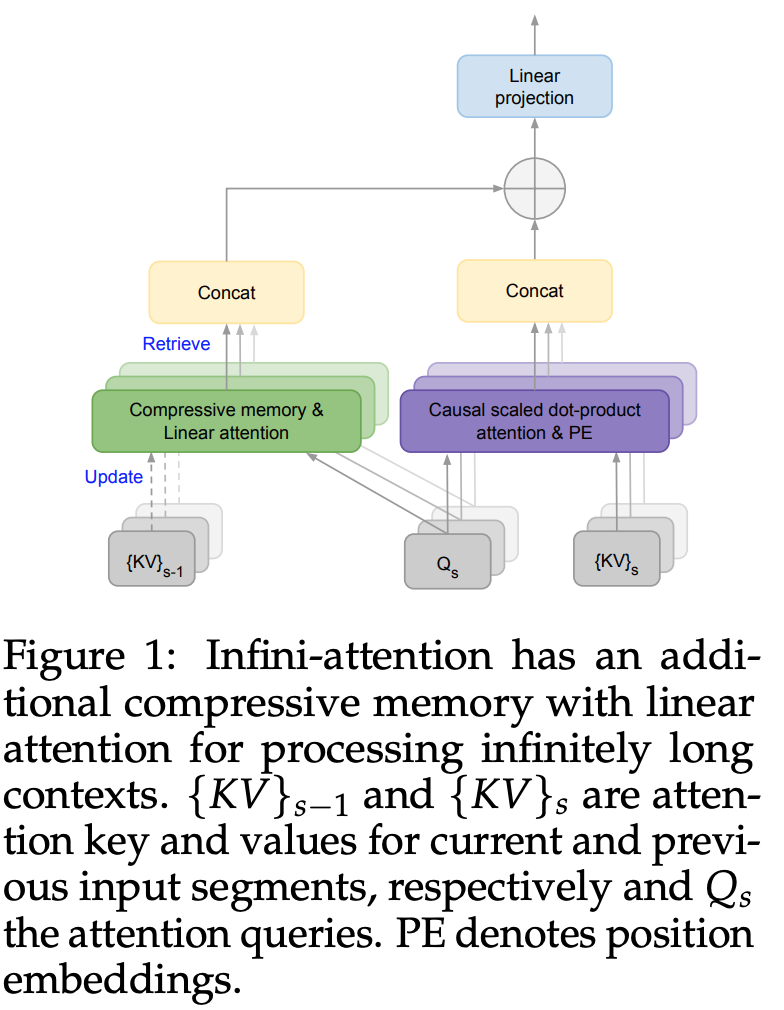
- Memory:
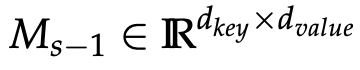
- Memory Retrieval:

- $Q\in \mathbb{R}^{N\times d_{key}}$
- $M_{s-1}\in \mathbb{R}^{d_{key}\times d_{value}}$
- $A_{mem}\in \mathbb{R}^{N\times d_{value}}$ (N: input segment length)
- $\sigma$: nonlinear activation (논문에서는 ELU+1)
- $z_{s-1}\in \mathbb{R}^{d_{key}}$: normalization term
- Memory Update:
- update linear:
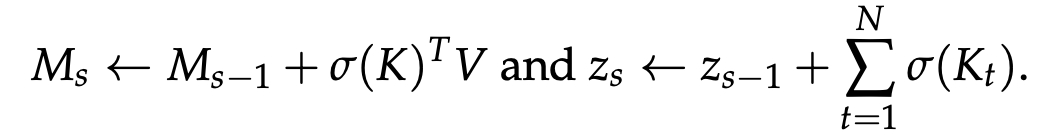
- update linear delta:
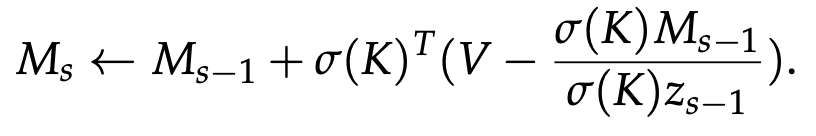
- update linear:
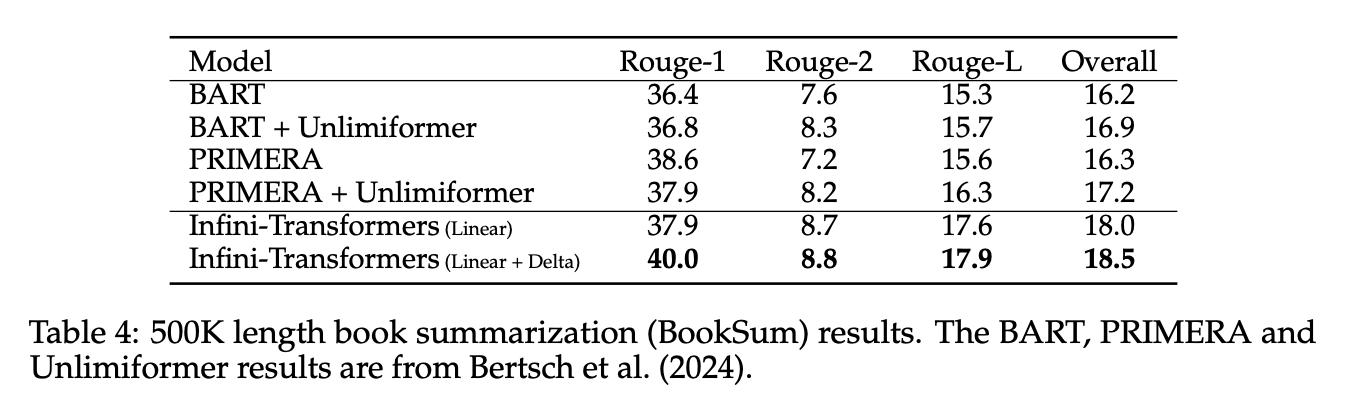
비교

실험