(논문 요약) DIFFERENTIAL TRANSFORMER (Paper)
핵심 내용
- Motivation: irrelevant information 의 attention 을 줄임.

- Differential Attention
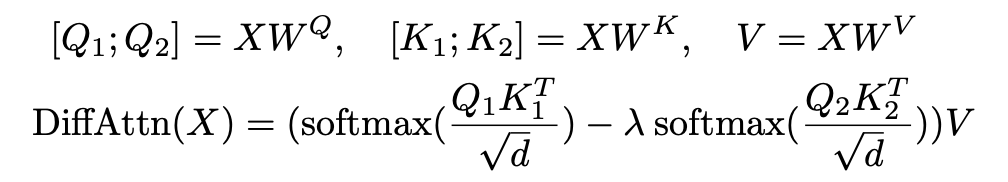
- $X\in\mathbb{R}^{N\times d_{model}}$
- $Q_1, Q_2, K_1, K_2\in\mathbb{R}^{N\times d}, V\in\mathbb{R}^{N\times 2d}$
- $\lambda = \exp(\lambda_{q_1}\cdot\lambda_{k_1}-\lambda_{q_2}\cdot\lambda_{k_2})+\lambda_{init}$
- $\lambda_{init} \in (0,1)$ is a constant.
- learnable parameters
- $W^Q, W^K, W^V\in\mathbb{R}^{d_{model}\times 2d}$
- $\lambda_{q_1},\lambda_{k_1}, \lambda_{q_2}, \lambda_{k_2}\in\mathbb{R}^d$
- MultiHead operation 구조

- Layer 구조
- $Y^l=$ MultiHead(GroupNorm($X^l$))$+X^l$
- $X^{l+1}$= SwiGLU(GroupNorm($Y^l$))$+Y^l$
- SwiGLU(X) = (swish$(XW^G) \odot XW_1) W_2$
- $W^G,W_1\in \mathbb{R}^{d_{model}\times \frac{8}{3}d_{model}}$
- $W_2\in \mathbb{R}^{\frac{8}{3}d_{model} \times d_{model}}$
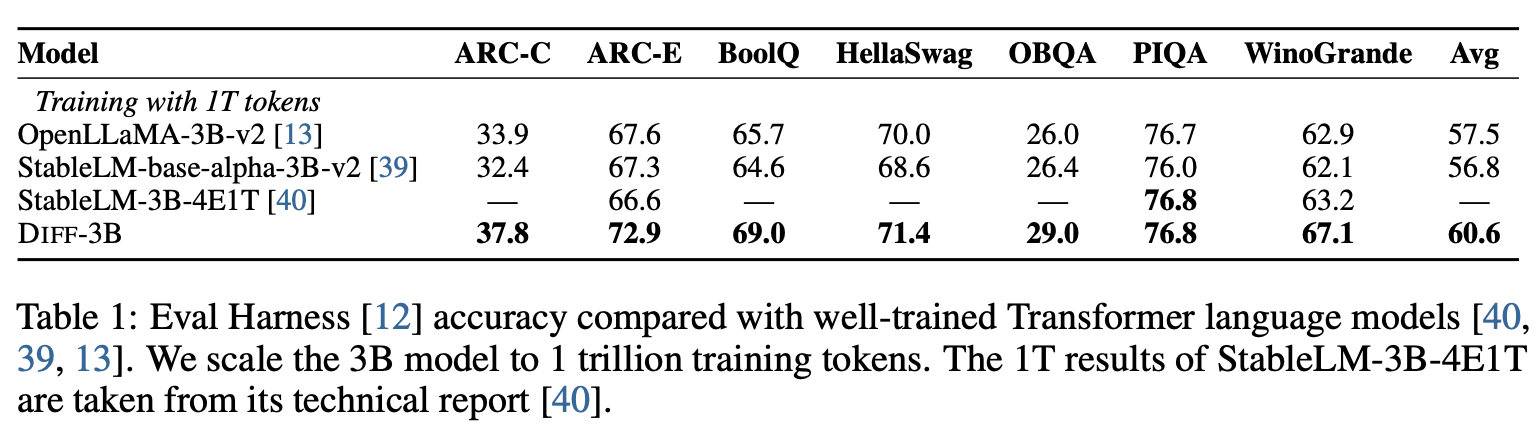
실험