(논문 요약) SPIRIT LM: Interleaved Spoken and Written Language Model (Paper)
핵심 내용
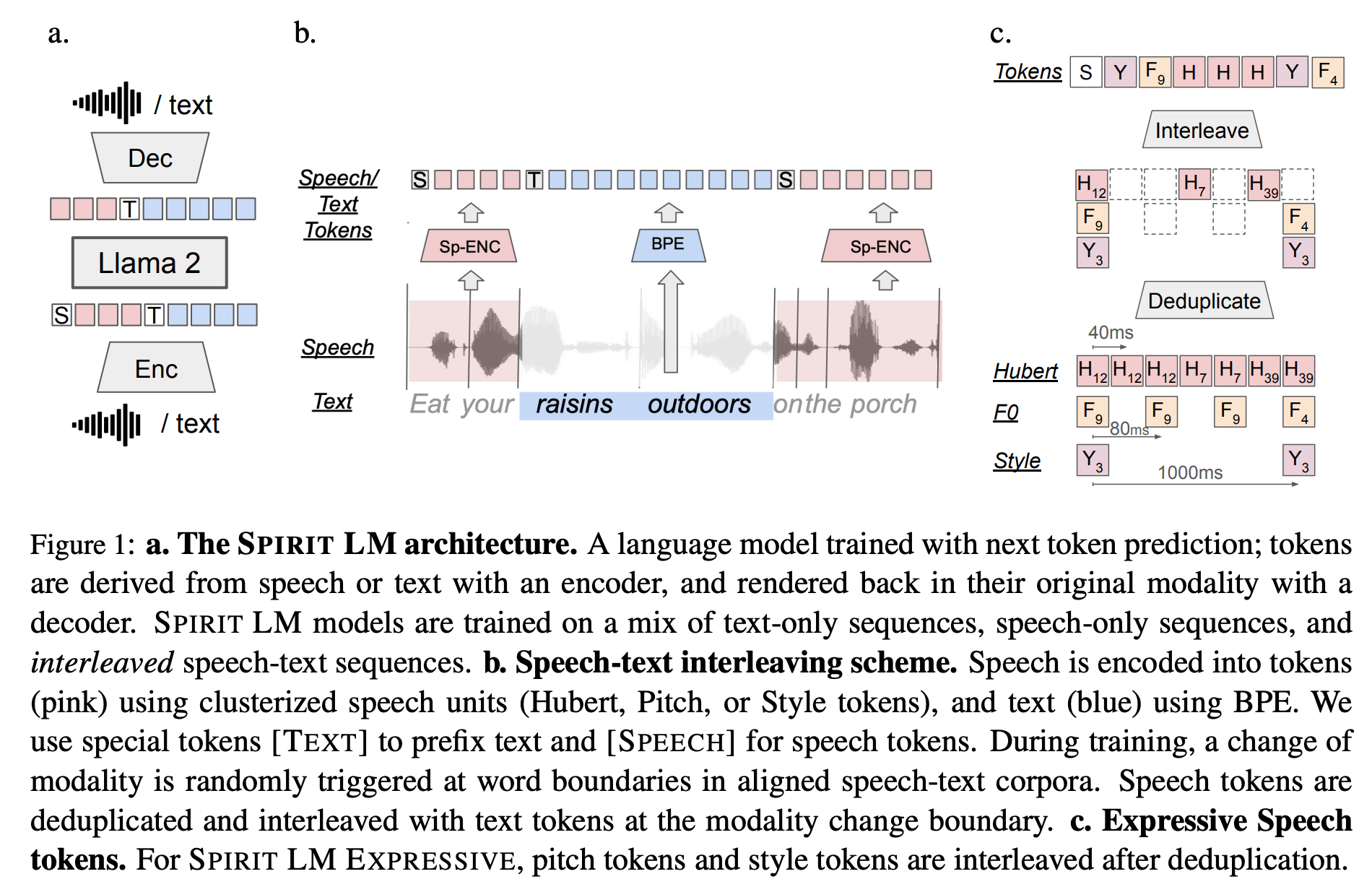
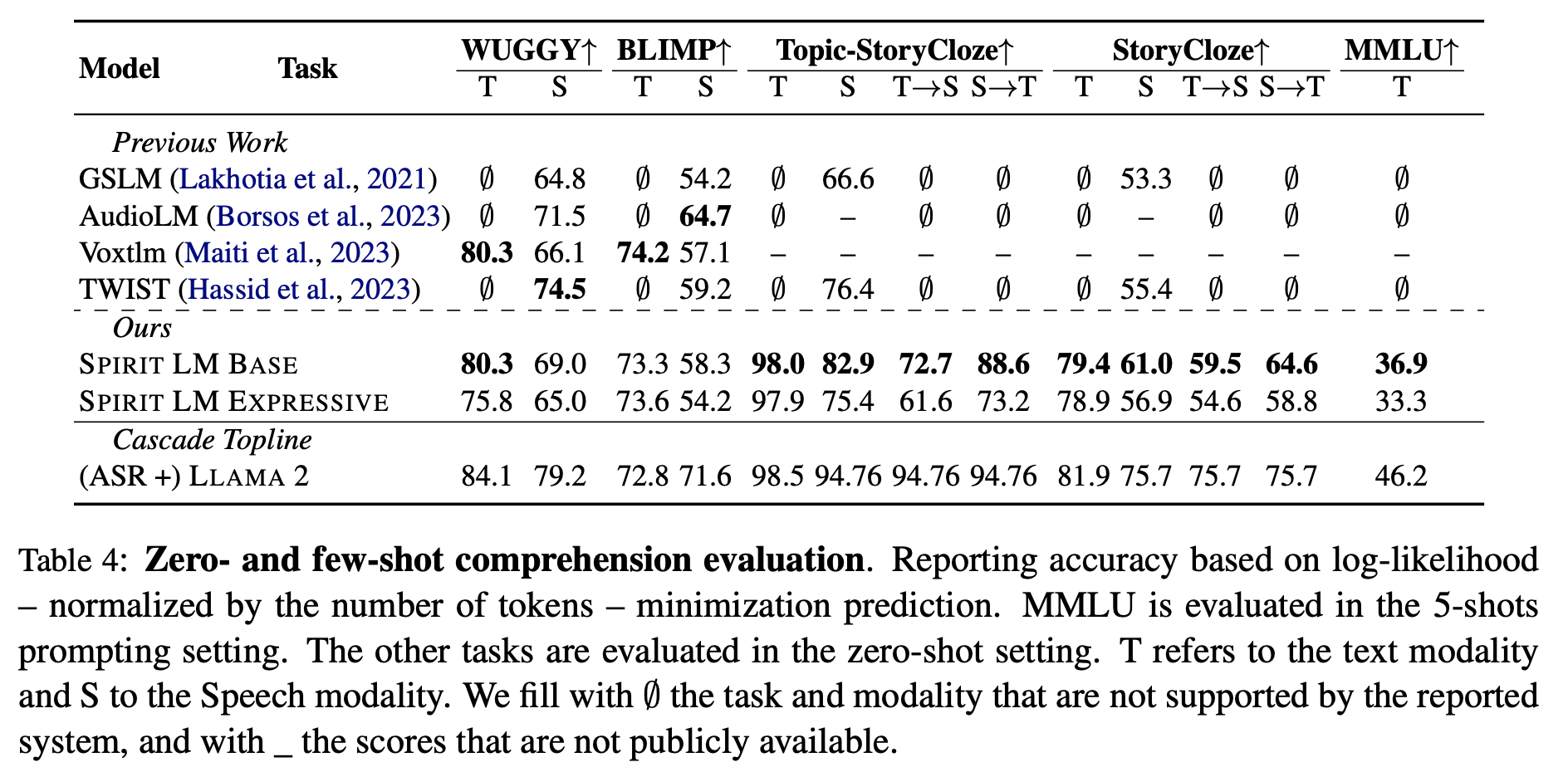
- Architecture
- Llama-2 7B
- HuBERT speech encoder
- HifiGAN vocoder trained on the Expresso dataset
- Embedding
- text: BPE
- speech phonetic units: HuBERT token
- Pitch token: VQ-VAE model trained on the F0 of the input speech
- Style token: speechprop features
- 학습: autoregressive loss
실험 결과