(논문 요약) Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet (paper)
feature 정의
- 2-layered Sparse Auto-Encoder 학습
- 1번째 layer (activation -> feature, which is higher dimension vector)
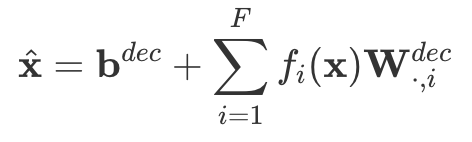
- 2번째 layer (feature -> activation dimension)
- loss 는 reconstruction + L1
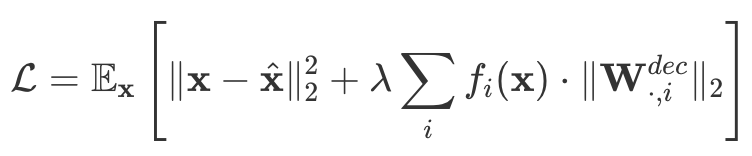
- decoder 의 weight 은 basis, 혹은 direction 으로 생각

- 1번째 layer (activation -> feature, which is higher dimension vector)
예시
- Descriptions of or references to the Golden Gate Bridge 를 34M Auto-Encoder 에 통과시켜 나온 feature 와의
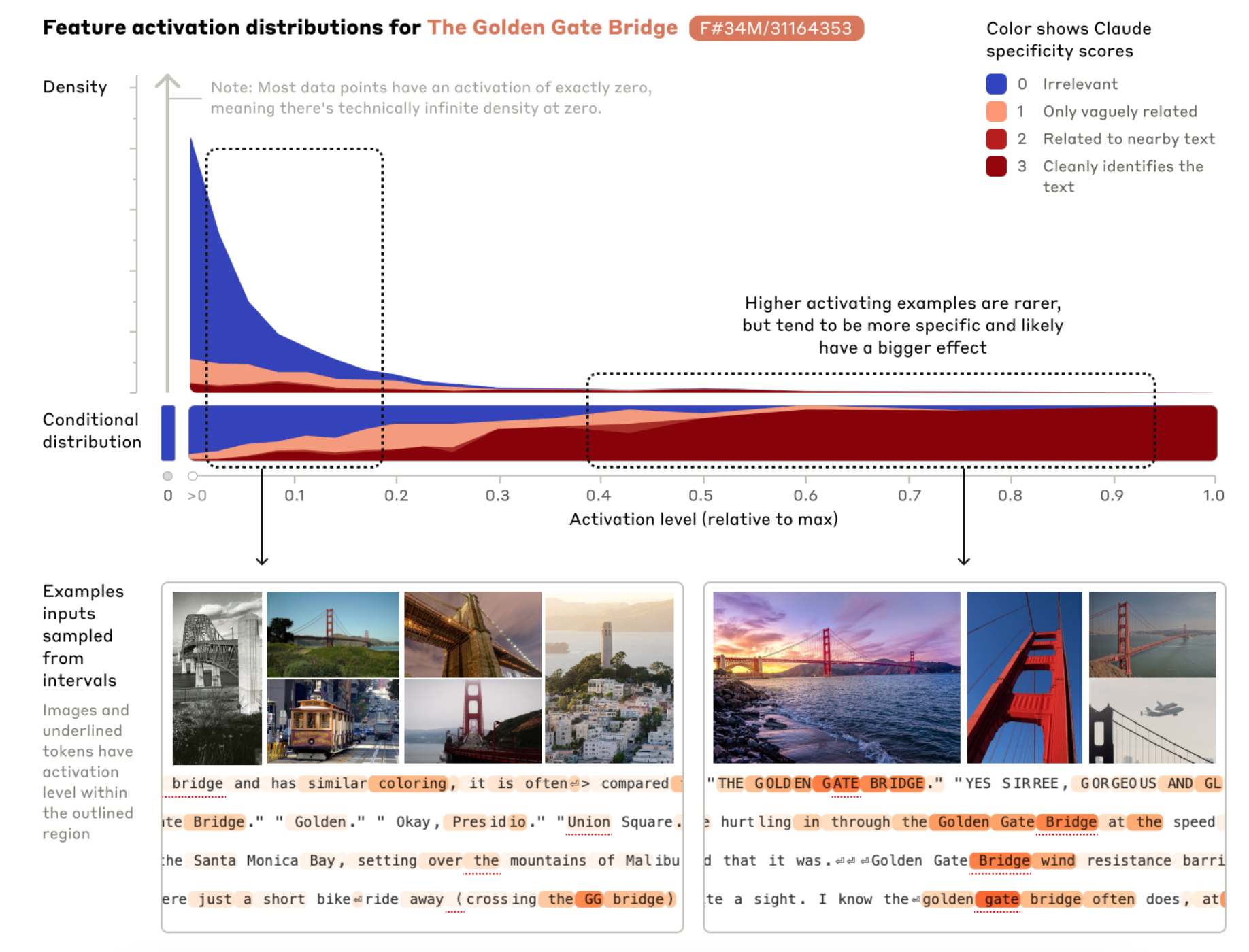
궁금증
- network 에서 activation 을 어떻게 뽑는지 모르겠음
- network 의 activation 을 그대로 쓰면 안되는지? 구지 higher dimension 으로 높이는게 필요할지?