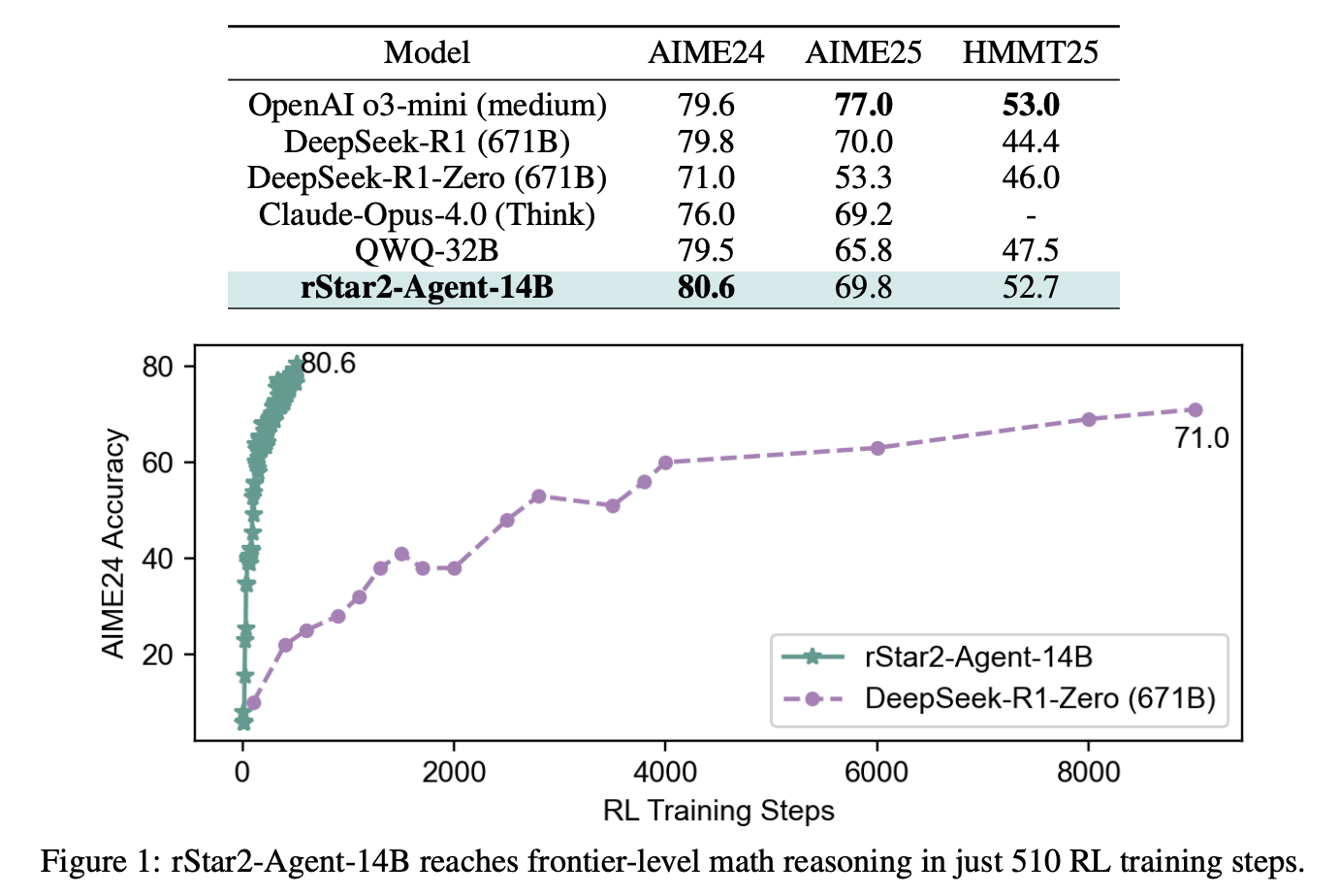
(논문 요약) rStar2-Agent: Agentic Reasoning Technical Report (Paper)
핵심 내용
- Model: Qwen3-14B
- 학습: RL only (Reasoning SFT 없음)
- GRPO-RoC: correct rollout 중 tool-use errors 나 incorrect formatting trajectory 는 덜 고름.
- Multi-RL stages
- stage 1: 42,000 개 수학문제, 길이 8K 미만
- stage 2: 300 step 이후, 길이 12K 미만
- stage 3: 잘 틀리는 문제 17,300 개에 집중
- 자원: 64개 MI300X GPU
- Reasoning with Tool (Python code) Use
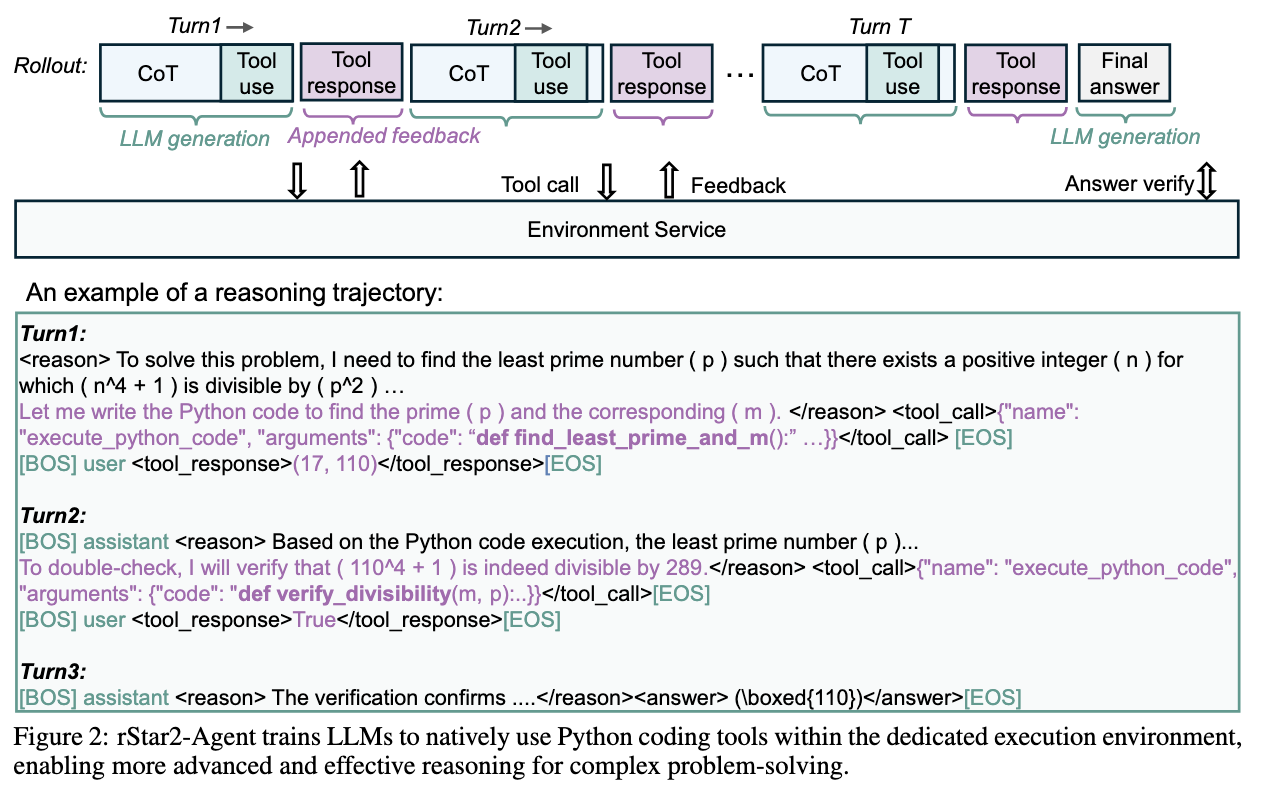
- Python code 예시 (on-the-fly 로 함수 생성)

실험 결과