(논문 요약) SAM 2: Segment Anything in Images and Videos (Paper)
핵심 내용
- 목표: video 에서 Promptable Visual Segmentation
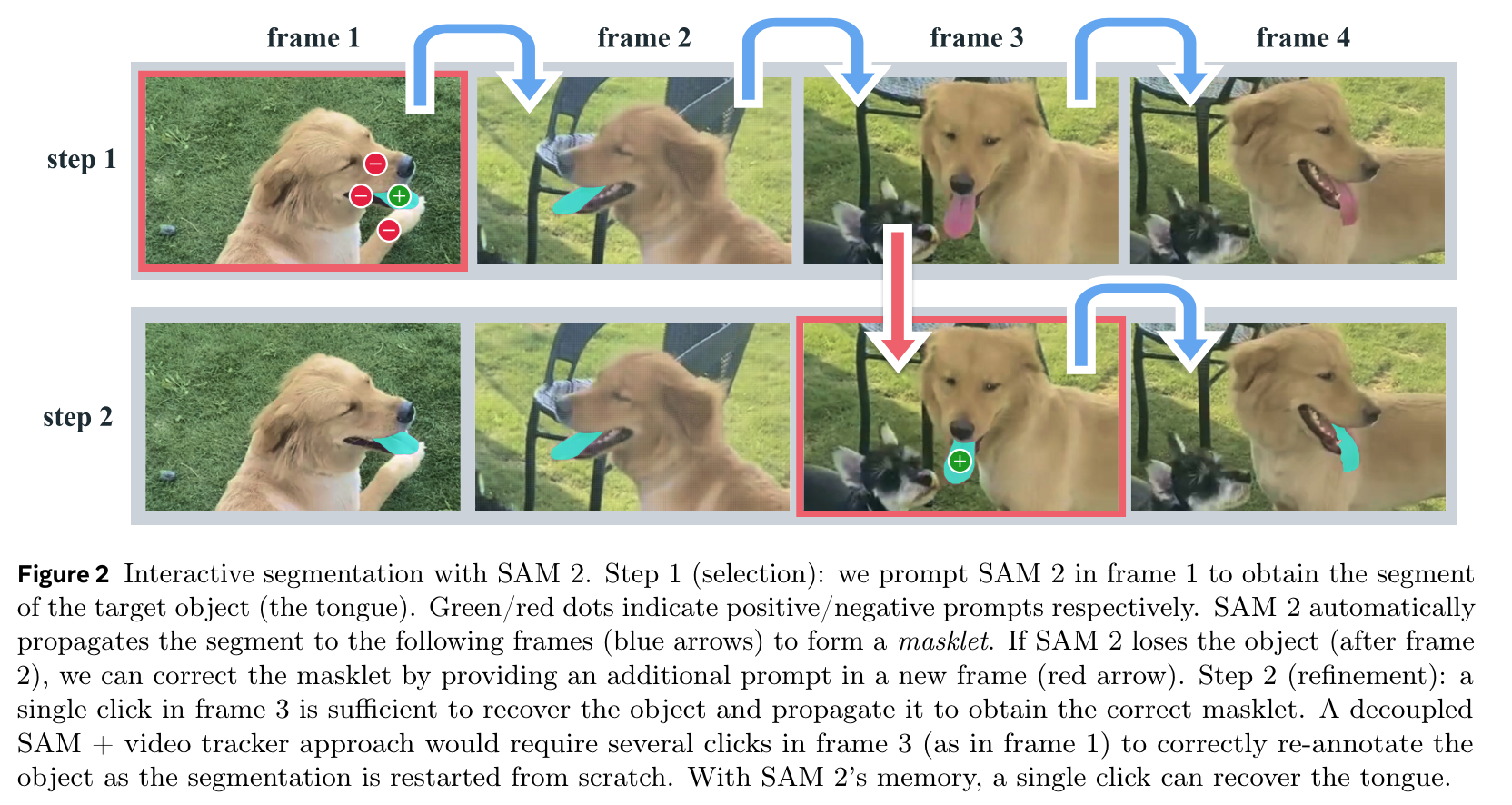
box, point, mask 로 prompt, memory bank, memory attention 도입

- SAM 과 다른점
- mask decoder: occlusion score 계산, encoder 를 ViT 에서 Hiera 로 변경, transposed conv 시 image encoding feature skip-connect
- mask prompt encoding 시 conv + frame embedding
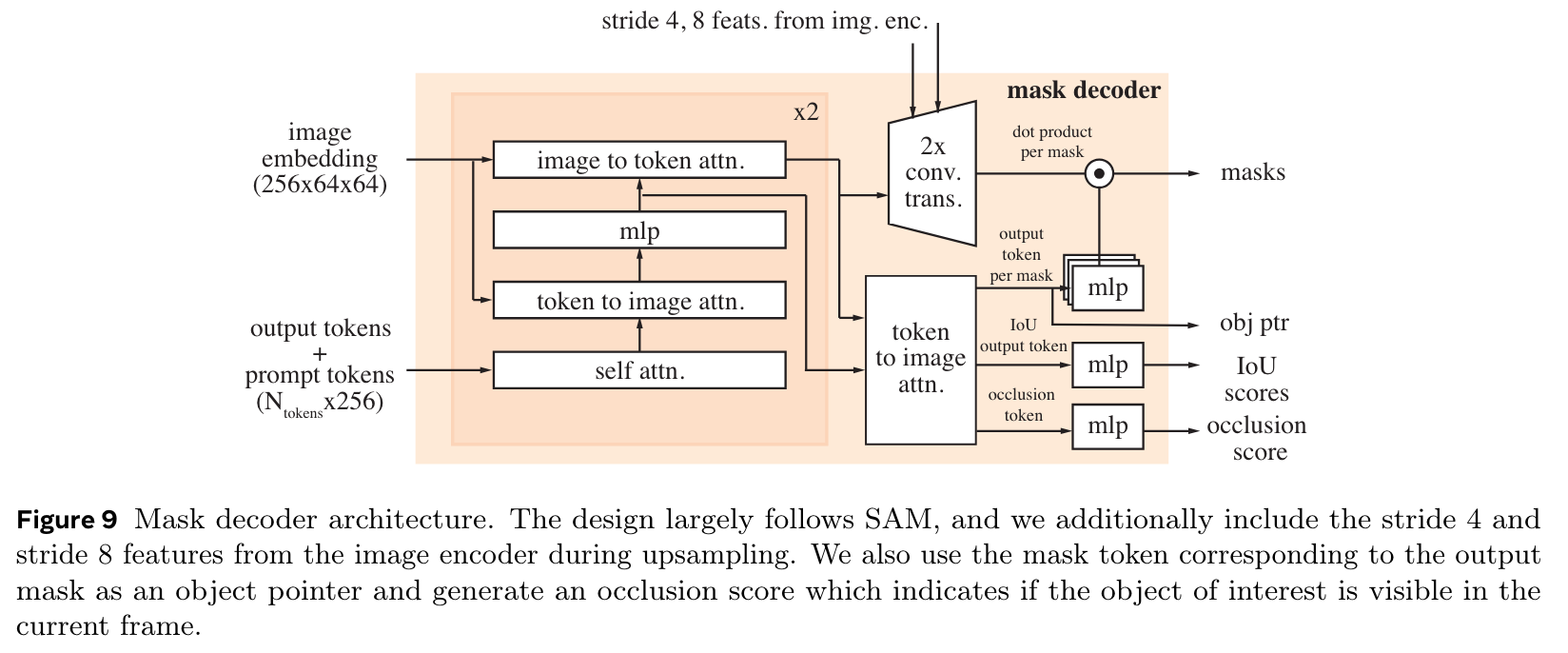
- memory: 과거 이미지들의 정보를 기록

- memory attention: $L$ transformer blocks, cross-attention with features in a memory bank
- memory encoder: output mask 를 conv-downsample, image encoding feature 더하고, conv
- memory bank 는 다음 정보를 가지고 있음
- recent $N$ frames
- object pointers (= vectors for objects to segment = output token per mask)
- 학습
- randomly, select 2 frames out of 8 frames for prompt
- sequentially predict the ground-truth masklet
- Initial prompt type: mask ($p=0.5$), a positive pixel ($p=0.25$), bounding box ($p=0.25$)
실험 결과
- 수집된 데이터
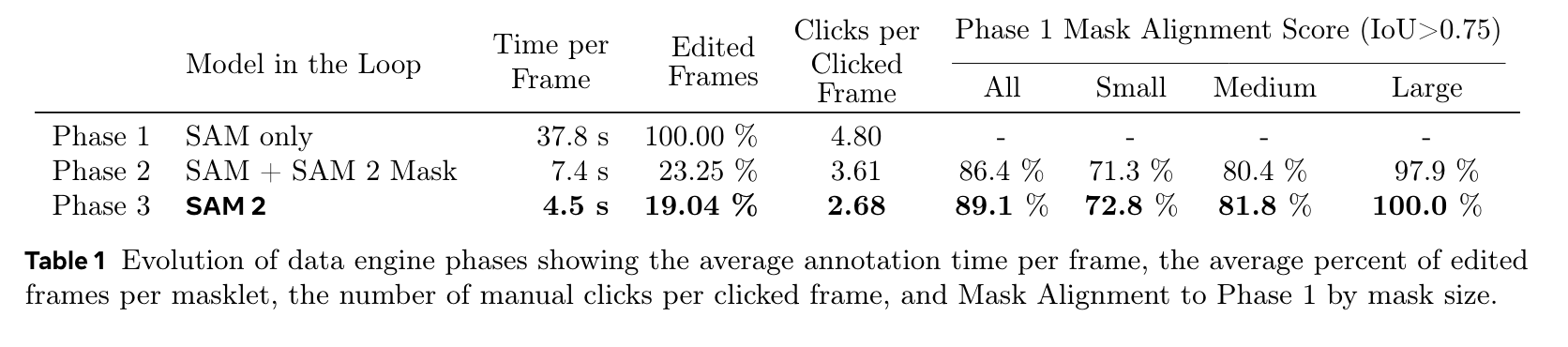
- Phase 1, SAM only: 개별 frame 을 SAM 으로 돌린후, 사람이 수정
- Phase 2, SAM + SAM2 Mask: Phase 1 데이터로, mask 가 prompt 인 SAM2 모델 학습. 첫번째 frame 을 SAM + editing tool 로 작업후, 모델 돌리고, 사람이 수정하며 데이터 확보
- Phase 3, SAM2: Phase 2 에서 얻어진 데이터로 학습된 SAM2 활용하여 사람이 수정하며 데이터 확보
- quality verification: satisfactory, unsatisfactory 판별하는 인력을 두고, satisfactory 이면 데이터에 추가, unsatisfactory 이면 다시 레이블

- video tasks

- image tasks
