(논문 요약) Segment Anything (Paper)
핵심 내용
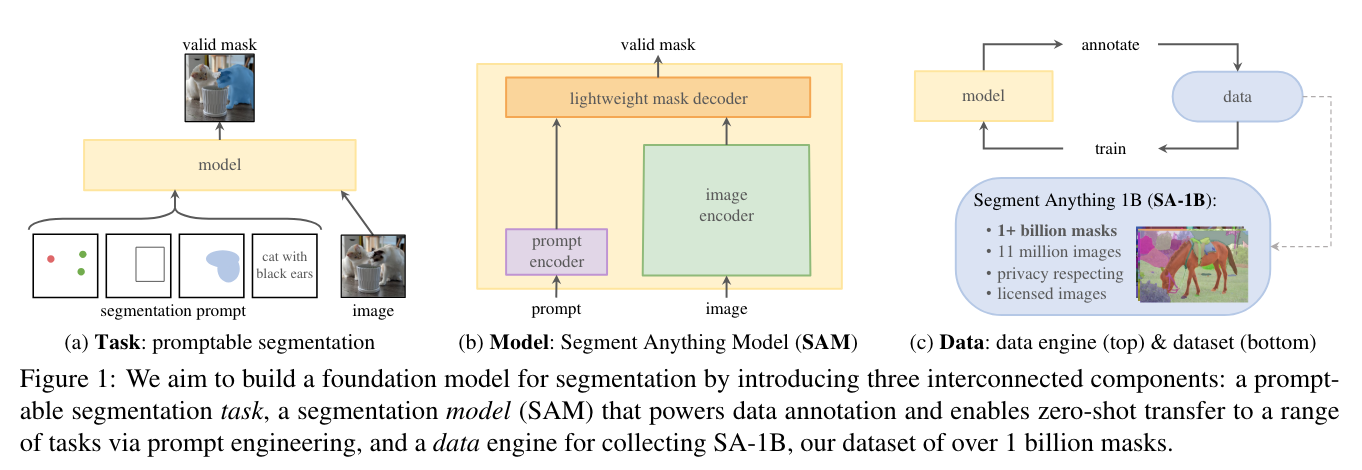
- concept: 사용자가 bbox, point, prompt 로 지정한 물체를 segment 하는 foundation model 개발
- lightweight mask decoder
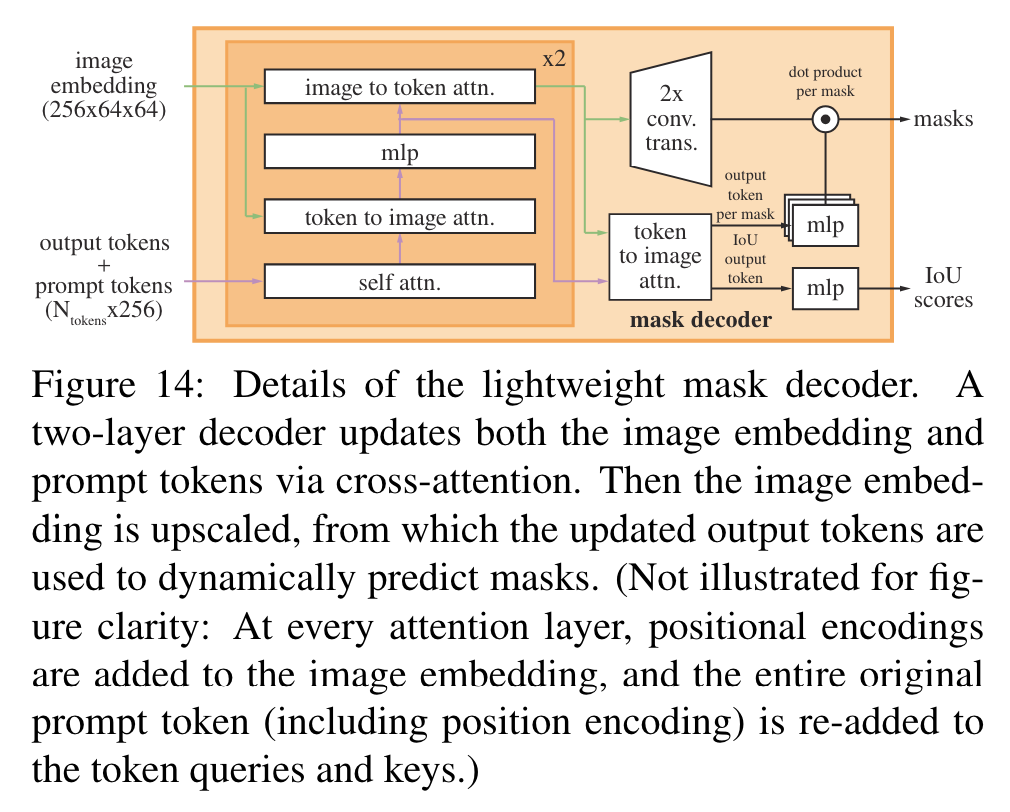
- output tokens: (reserved) learned embeddings
- X to Y attn: X 가 query, Y 가 key, value 인 attention
- 총 3개인 token output 을 각각 mlp 통과시켜서 feature 생성 후, conv 통과한 feature 와 dot product (같은 channel 개수 맞춰줌)
- 4번째 token output 을, 3개 output 들의 IoU 를 예측하도록 학습
- lightweight mask decoder
- 데이터
- 11M images, 1B masks
- augomatic data engine
- train iteration 을 돌수록, augmentation 더 심하게 주면서 학습 (매 iteration 마다 사람이 체크)
- IoU prediction 하는 모델을 학습하여, threshold >0.88 인 마스크만 남김
- 다른 값의 threshold 로 생성된 mask 2개의 IoU 가 95 이상인 마스크만 남김
- image 95% 이상을 차지하거나 100 pixel 이하 마스크는 삭제
- 100 pixel 이하의 hole 은 filling
- 학습
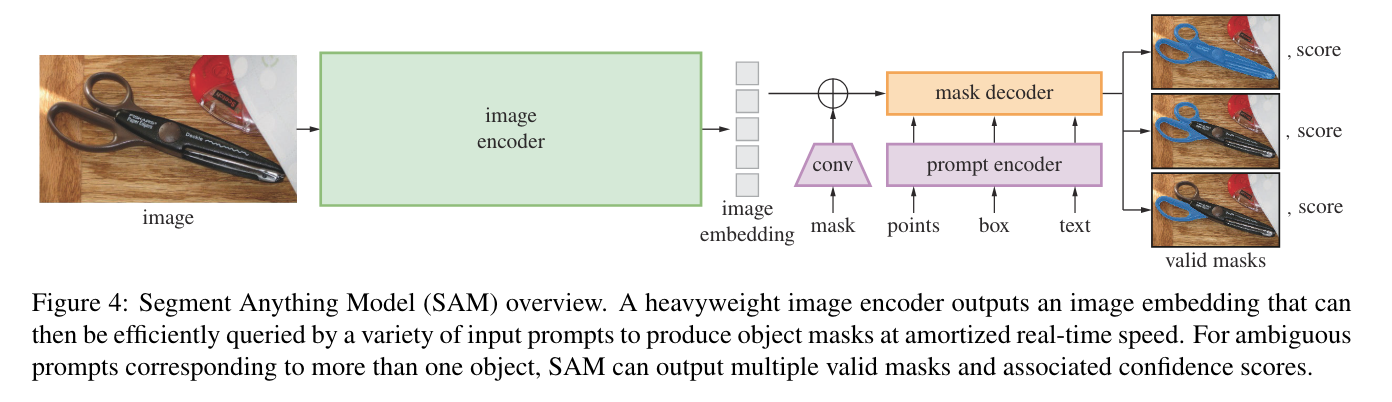
- loss: Focal loss + dice loss (backprop with least loss among 3 output heads)
- image encoder: MAE-pretrained ViT
- points, box: positional embedding + learned embedding for each prompt type
- text: CLIP embedding
- mask 3개를 생성 (예시에서는, 가위 전체, 양쪽 손잡이, 한쪽 손잡이에 해당하는 mask 가 생성됨)
실험 결과
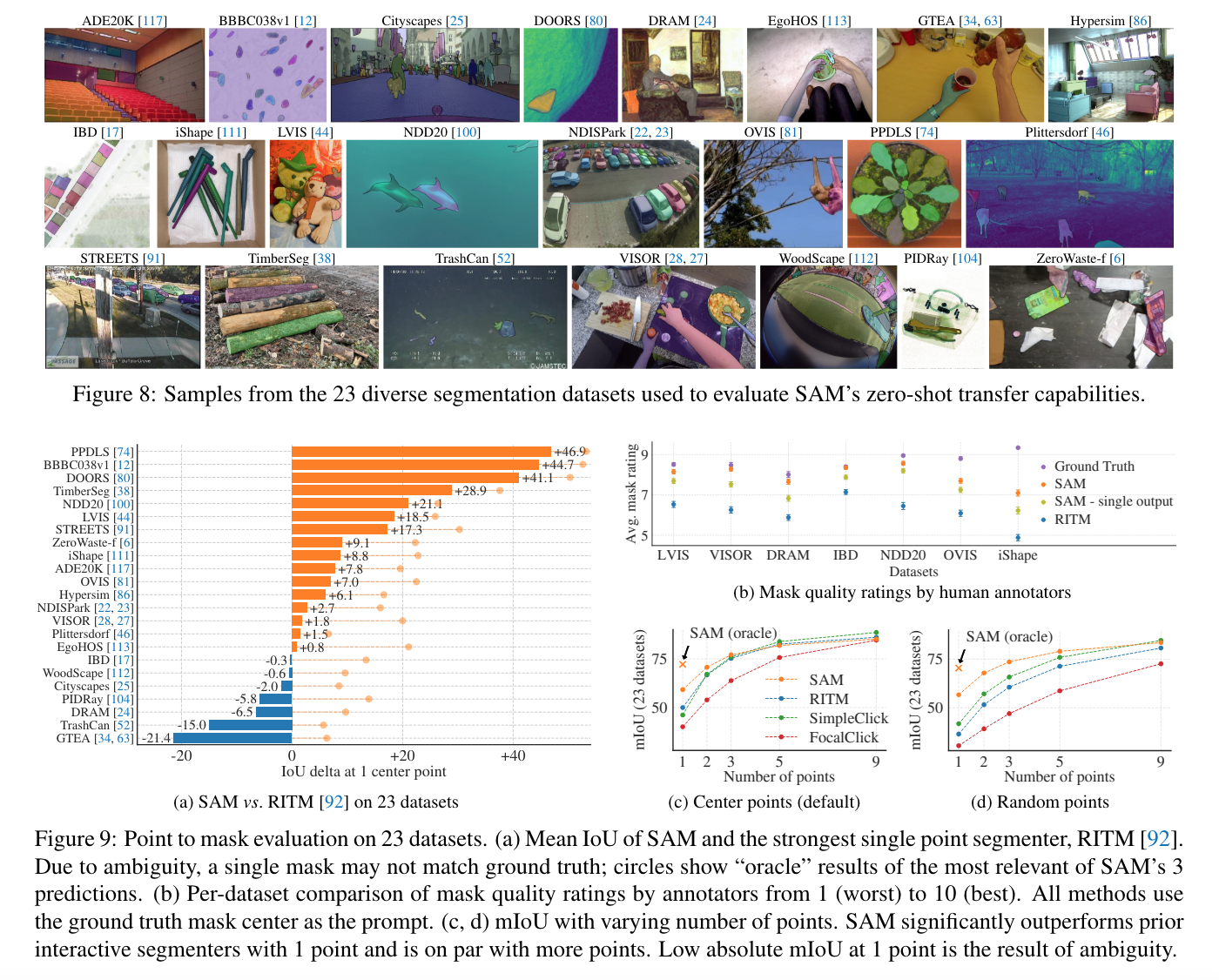
- example
