(논문 요약) Movie Gen: A Cast of Media Foundation Models (paper)
핵심 내용
- 생성 예시
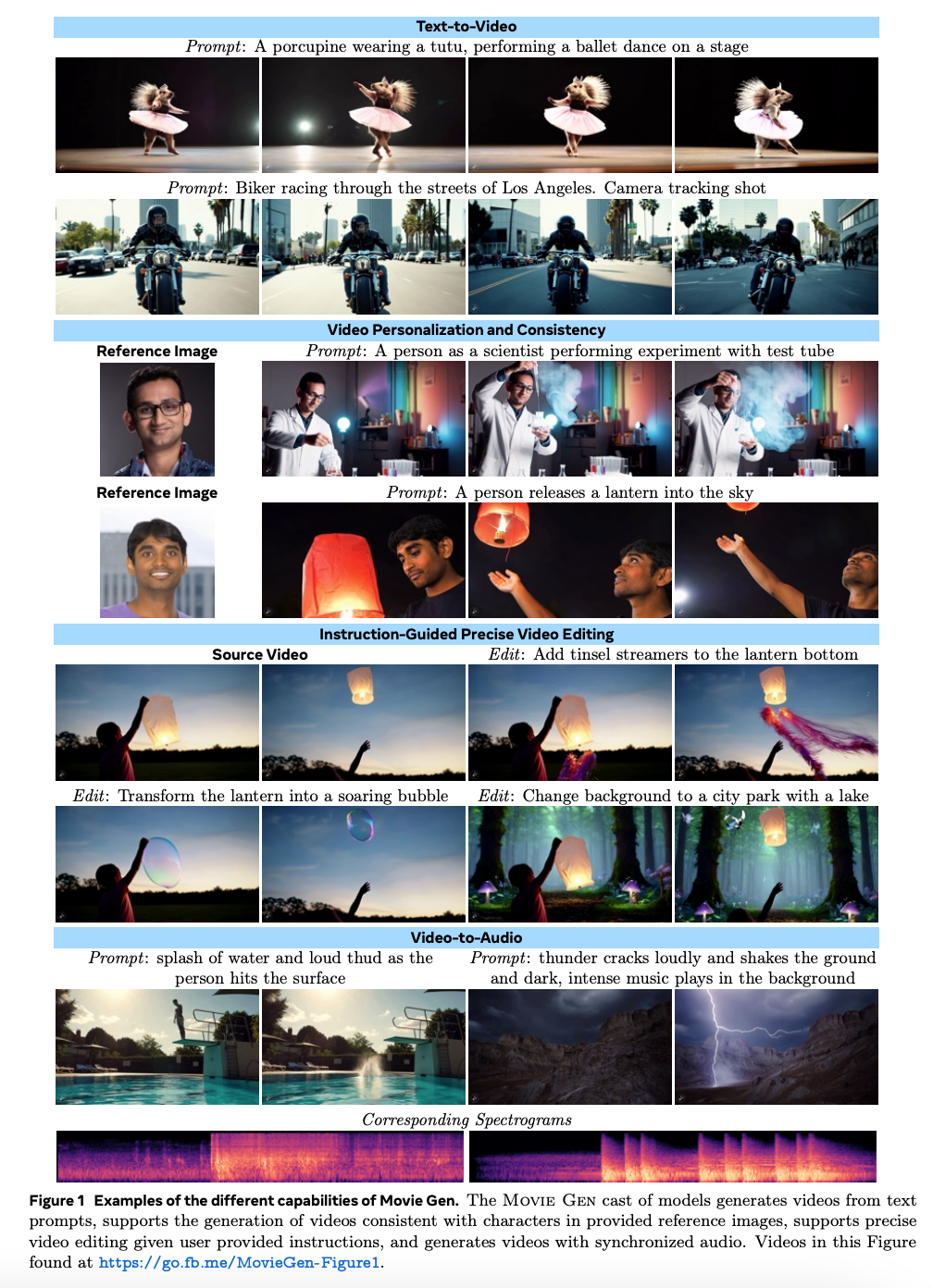
- Movie Gen Video 와 Movie Gen Audio 로 구성됨
- 전체 Training 순서
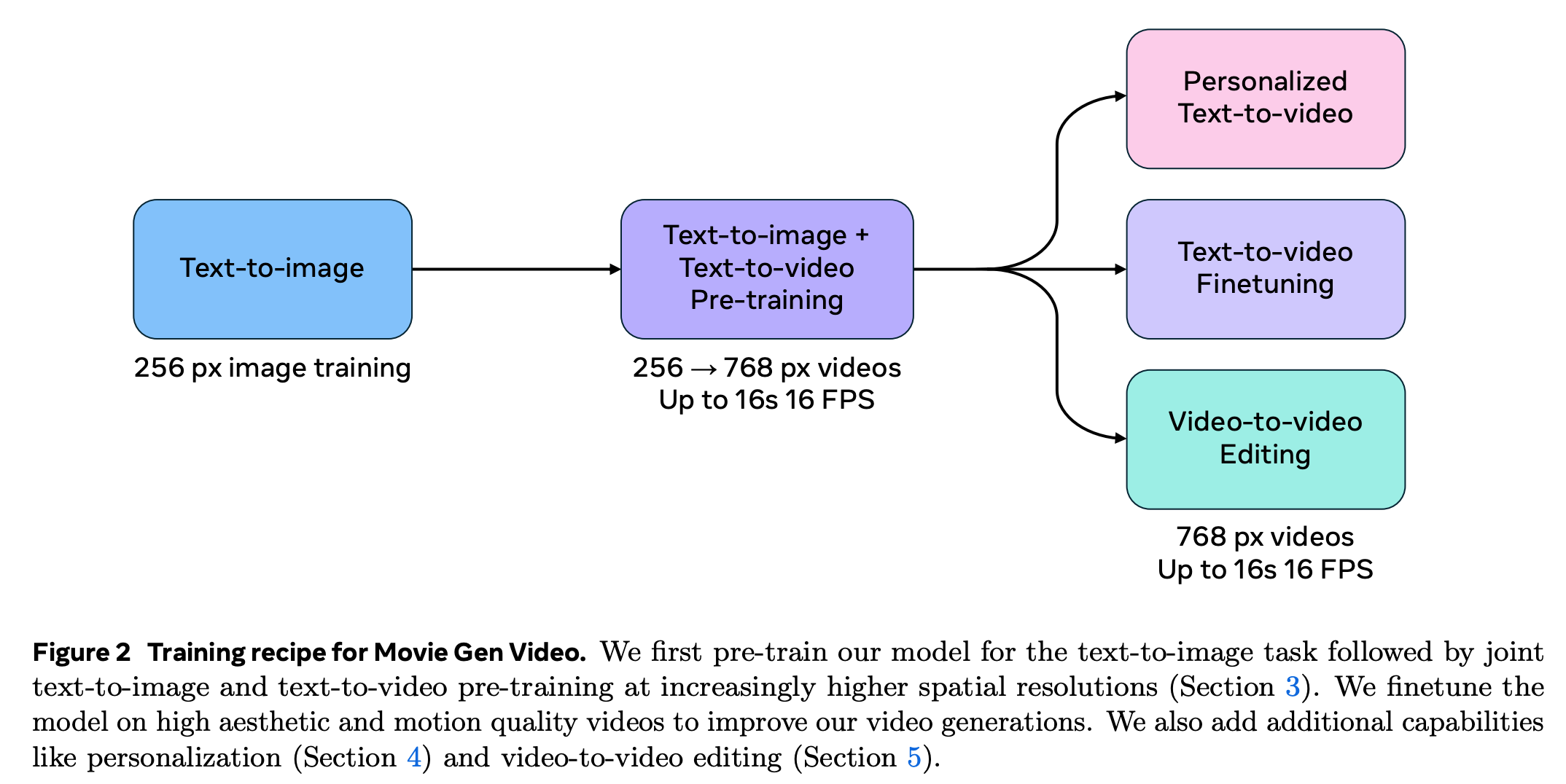
Movie Gen Video
- 30B transformer
- generate 16 seconds video at 16 fps
- pretrain on $\mathcal{O}(100)$M videos and $\mathcal{O}(1)$B images
- learns about the visual world by ‘watching’ videos.
- supervised finetuning on a small set of curated high-quality videos and text captions.
- TAE (Temporal Autoencoder) 를 사용하여 temporal 방향으로 압축된 video feature 뽑음.
- 비디오 길이가 긴 경우, overlapped chunk 로 자른 뒤 video feature 를 뽑고, 겹치는 구간은 linear ramping function 을 weight 로 하여 interpolation.
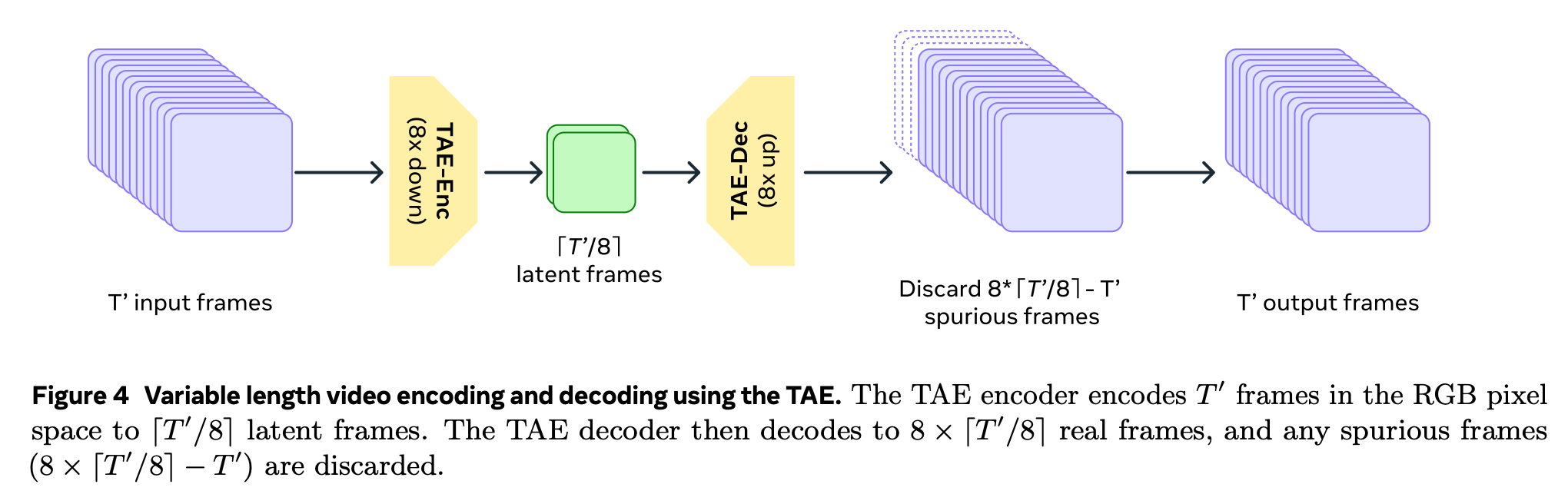
- 비디오 길이가 긴 경우, overlapped chunk 로 자른 뒤 video feature 를 뽑고, 겹치는 구간은 linear ramping function 을 weight 로 하여 interpolation.
- Flow Matching framework 사용.
- $X_1$: feature of a video clip, $X_0$: sample from Gaussian
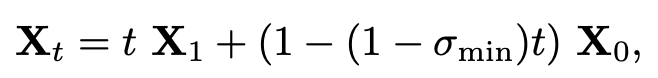
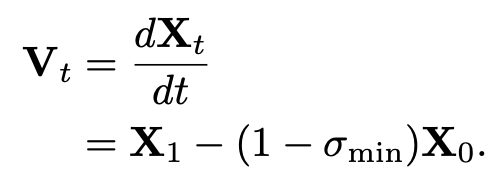
- 학습:
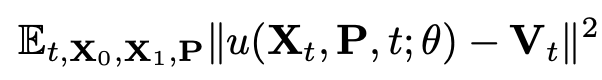
- inference: $X_0$ 샘플 후, 네트워크에서 나온 $V_t$ 와 ODE solver 사용하여 $X_1$ 생성.
- 전체 흐름
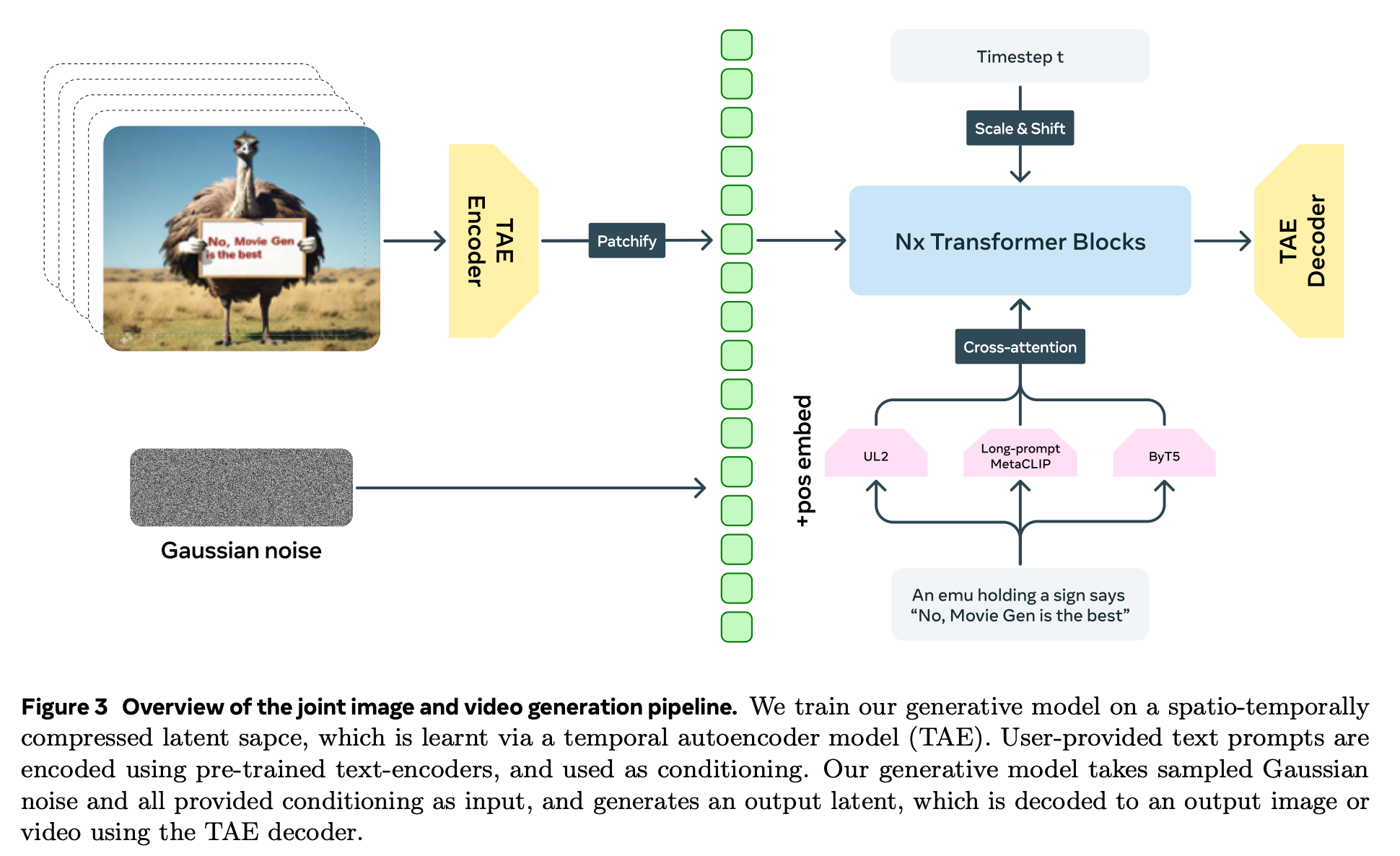
- 기타 사항
- outlier penalty loss 로 feature 값이 튀는 것 방지.
- 별도의 upsampling transformer 로 화질 개선 (576 x 1008) -> (1080 x 1920).
Movie Gen Audio
- 13B transformer
- generate video-to-audio or text-to-audio
- pretrain on $\mathcal{O}(1)$M hours of audio, $\mathcal{O}(100)$K video+audio cinematics
- supervised finetuning on a small set of curated higher quality (text, audio) and (video, text, audio) data
- diffusion transformer (DiT) 기반의 Flow Matching framework 사용

- overlapping 처리는 video 와 마찬가지로 linear ramping function 활용하여 합침.
- 전체 흐름
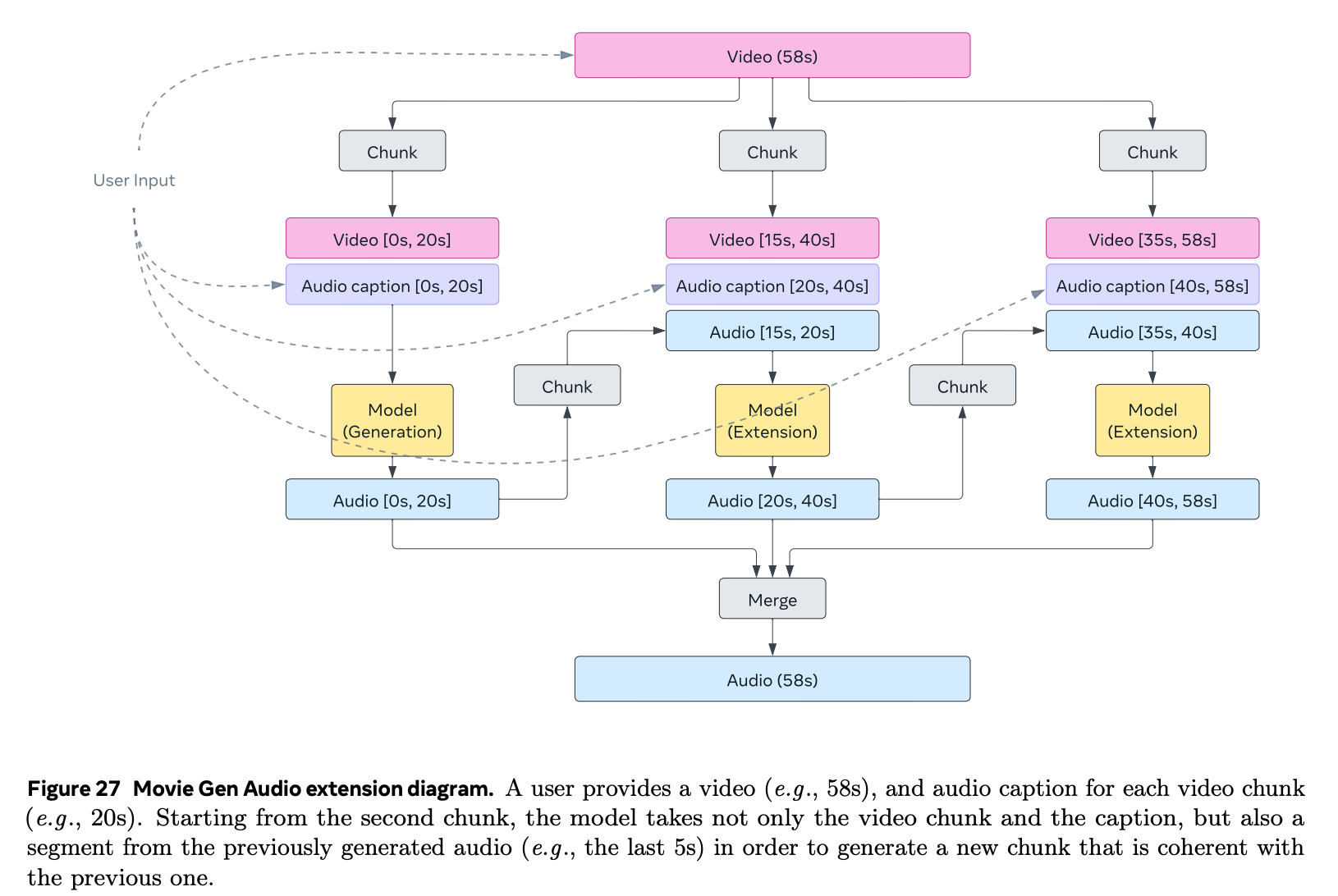
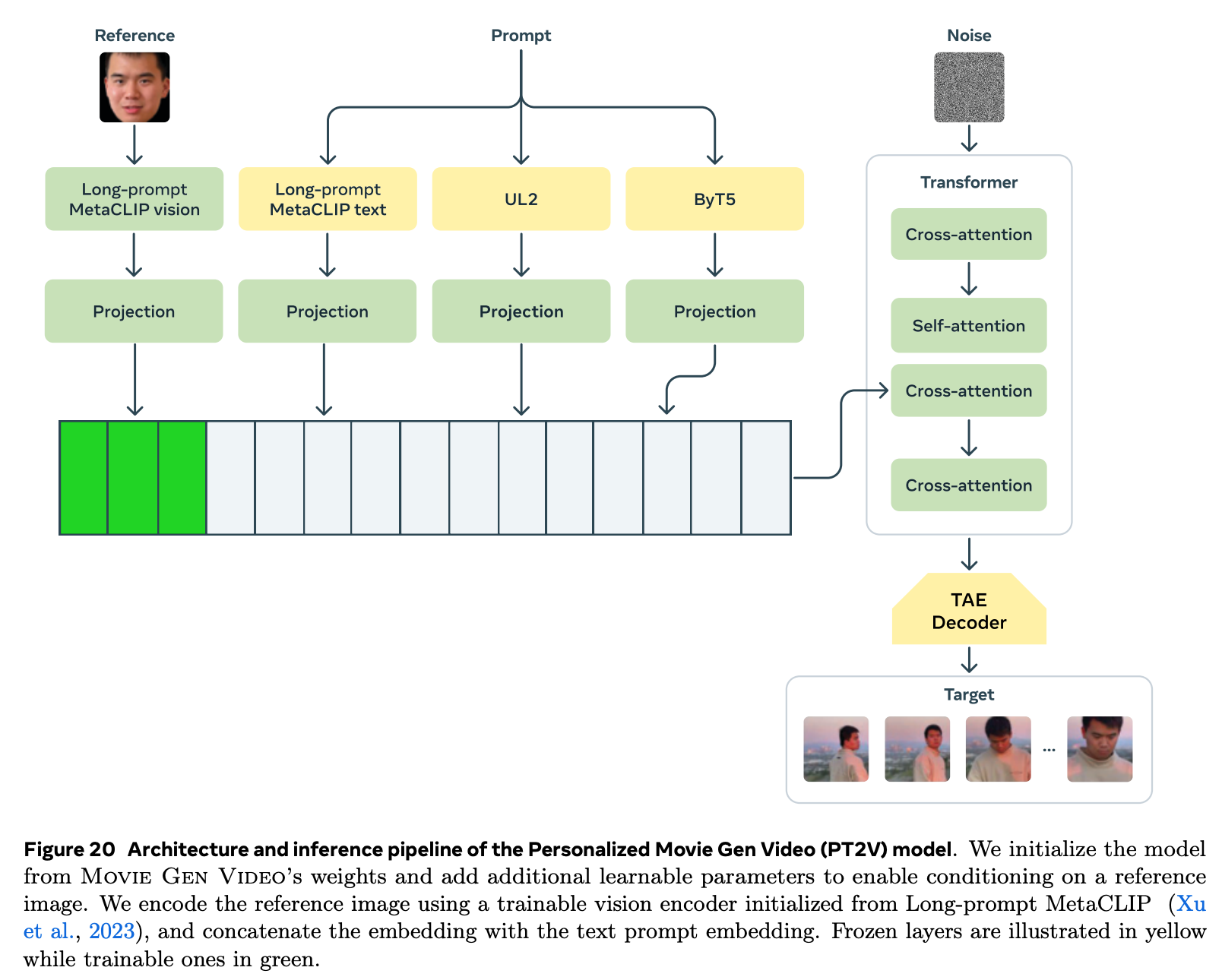
Video personalization
- 네트워크 추가 학습을 통해 personalization 실현
- text-video pair 에서 reference image 를 추가
- paired data: 특정 인물의 사진이 들어간 video clip 에서 image 샘플 5개 sample ($\mathcal{O}(10)$M pairs)
- real cross paired data: 같은 video 의 다른 view ($\mathcal{O}(10)$K pairs)
- synthetic cross paired data: 외부 모델 사용하여 reference image 를 다양하게 생성 ($\mathcal{O}(1)$M pairs)
Instruction-Guided Precise Video Editing

- Stage I: Single-frame Video Editing - image editing dataset 사용.
- Stage II: Multi-frame Video Editing
- Animated Frame Editing: image 1장을 augment 하여 이어붙여 video 만듬.
- Generative Instruction-Guided Video Segmentation: DINO 와 SAM2 로 segmentation mask 생성.

- Stage III: Video Editing via Backtranslation - Stage II 학습된 모델로 inference 돌린 뒤, context 를 수정하여 반대 방향으로 editing 하도록 학습.
