(논문 요약) Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget (Paper)
핵심 내용
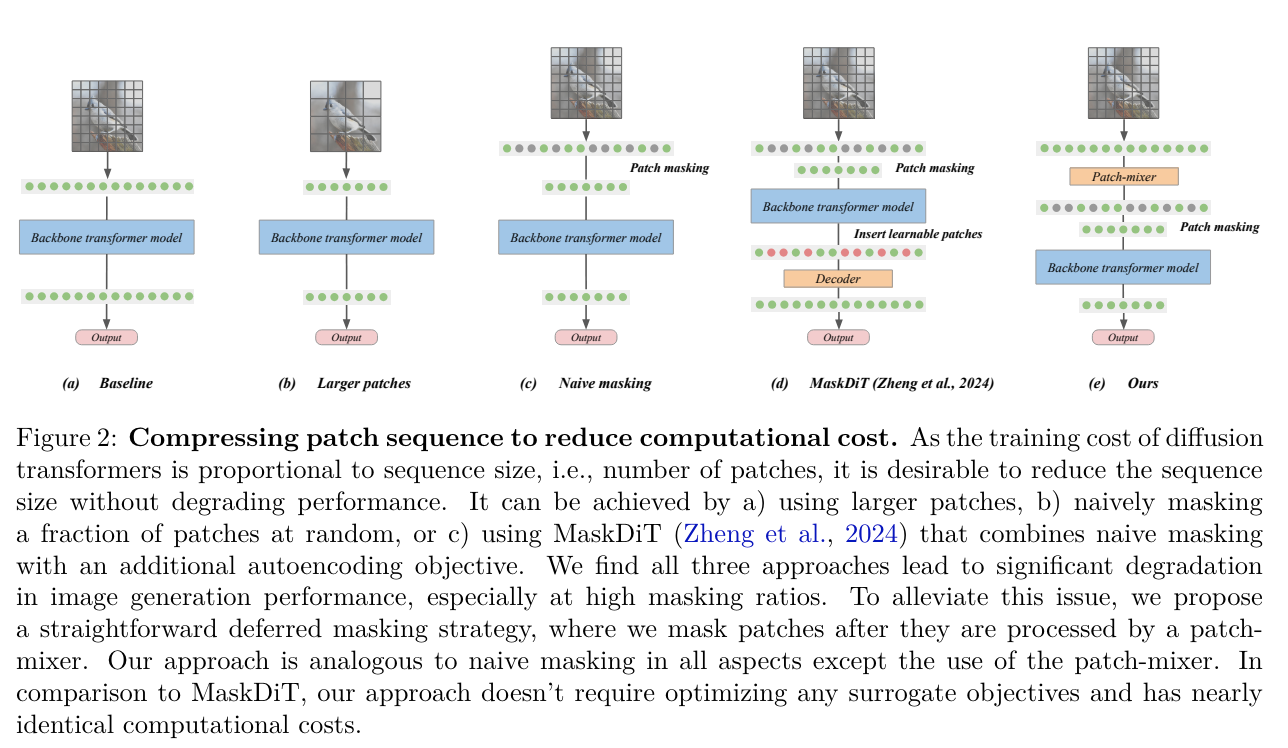
- randomly mask up to 75% of the image patches during training
- deferred masking strategy: preprocesses all patches using a patch-mixer (few transformer layers), and then mask
- data: 37M publicly available real and synthetic images
- model: 1.16B sparse transformer
- training cost: $1,890 (118× lower cost than stable diffusion models, 14× lower cost than SOTA)

실험 결과
- cost-effectiveness

- generation 예시
