(논문 요약) Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks (Paper)
핵심 내용
- 다양한 granularity 의 데이터 학습 vision foundation model
- caption 의 granularity
- object boundary 의 granularity
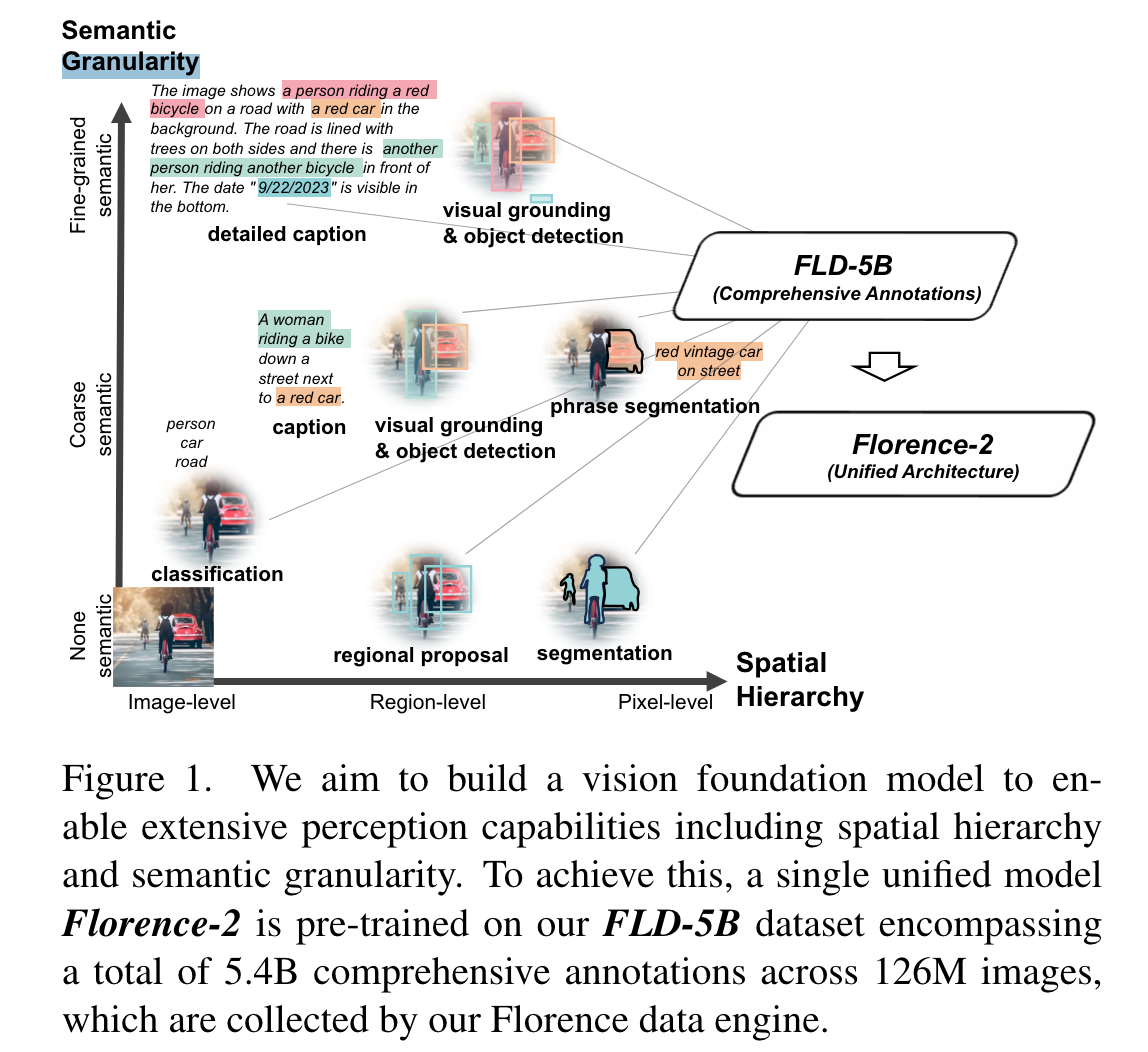
Architecture
- encoder-decoder 구조 (초기 모델이라 그런듯함)
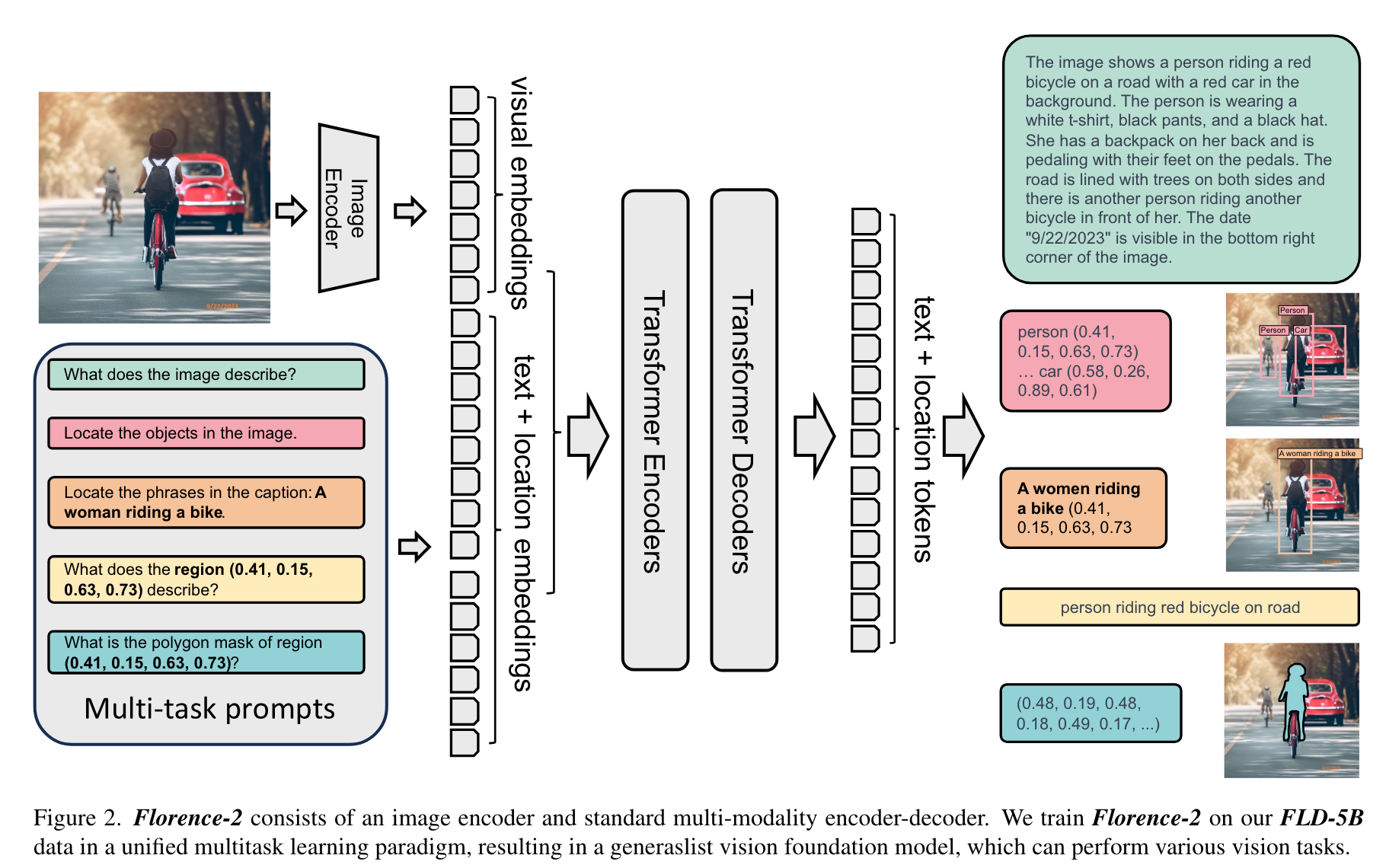
데이터
- image: 126M (ImageNet-22k, Object 365, Open Images, Conceptual Captions, LAION)
- 1차 annotation: specialist models (e.g. DINO object detector, Azure OCR, SAM, Grounding DINO)
- flitering
- excessive objects 제거
- dependency parsing tree 에서 node 의 degree 가 작은것들 제거
- NMS 로 noisy boxes 제거
- pronouns, abstract concepts 제거
- (코드 공개 안되어 있고, appendix 에도 구체적인 내용 없음)
- 1차 annotation 을 filtering 후, 모델 학습한 뒤, model inference 결과를 데이터에 추가 (했다고함)
- 최종 annotation 숫자
- 500M text
- 1.3B region-text
- 3.6B text-phrase-region

실험 결과
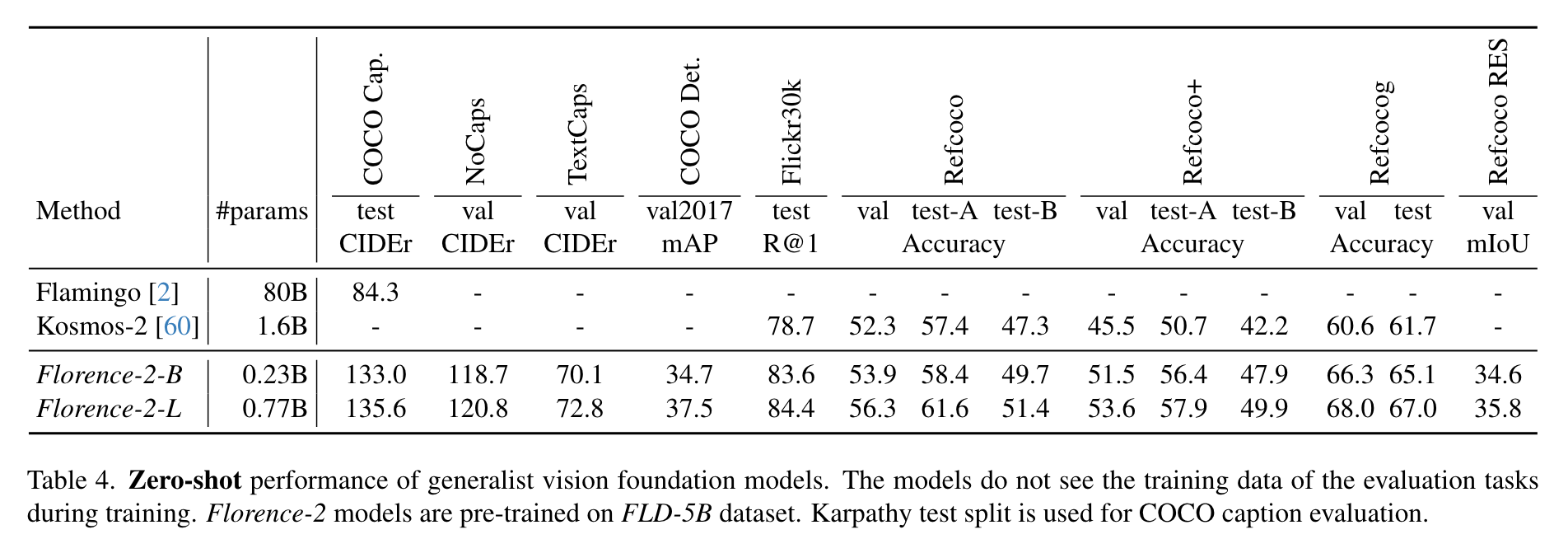
- finetuning data 없이 학습한 모델
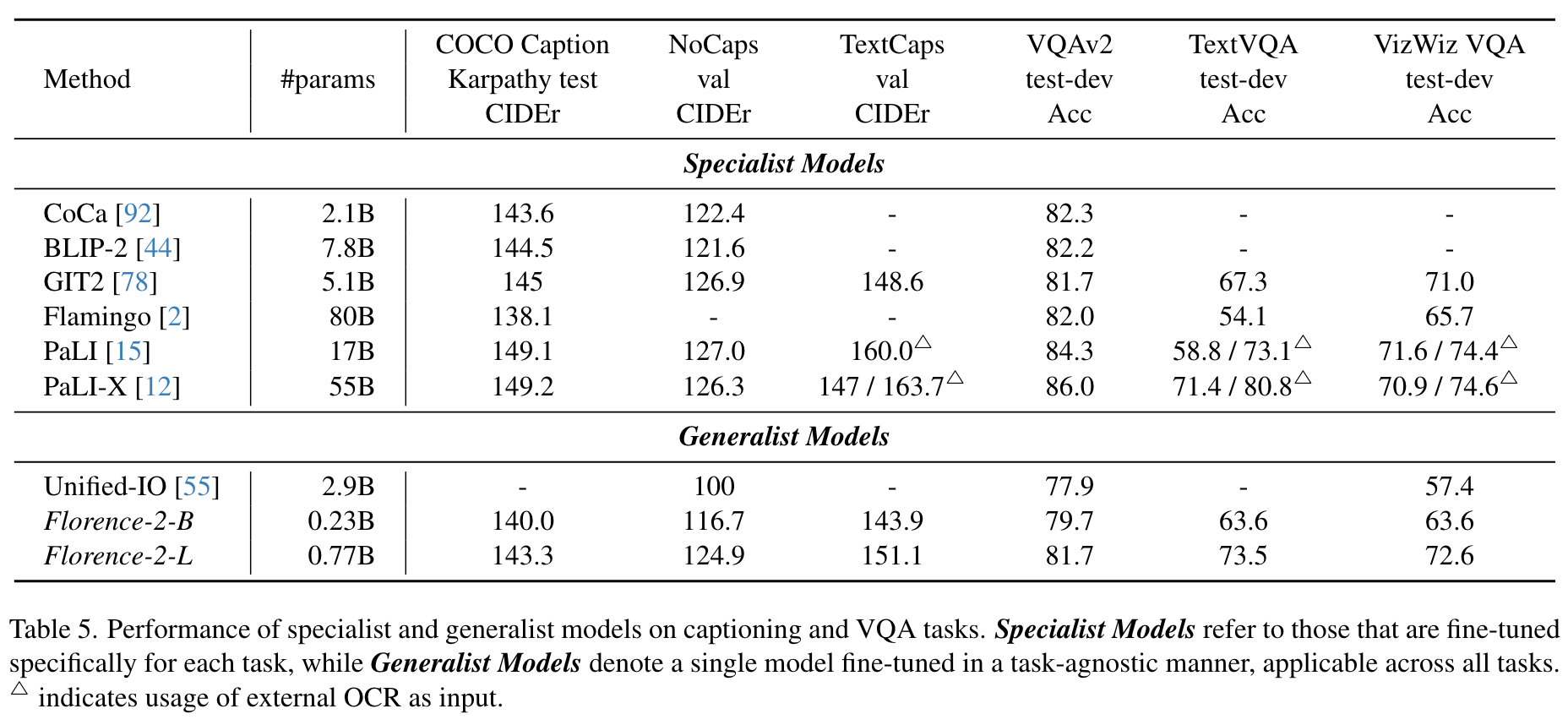
- finetuning data 다 합쳐서 학습한 모델
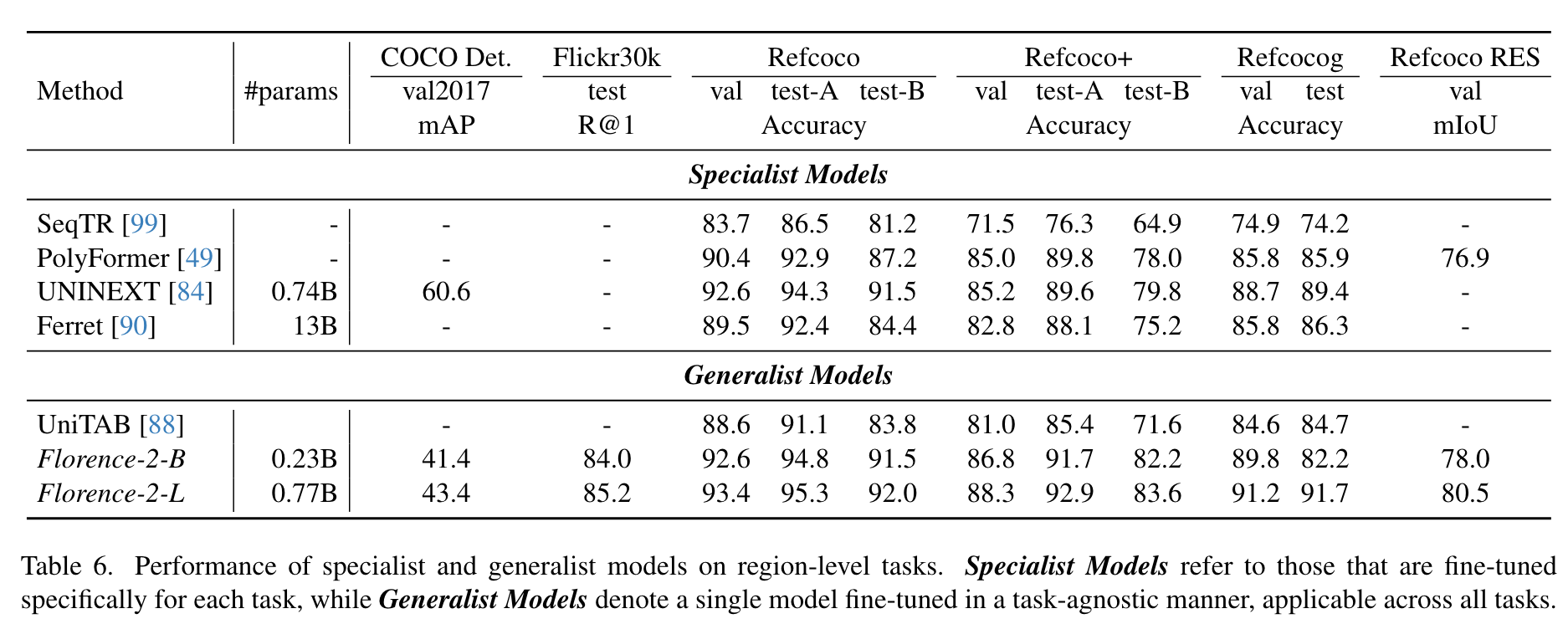
기타 내용
- finetuning data
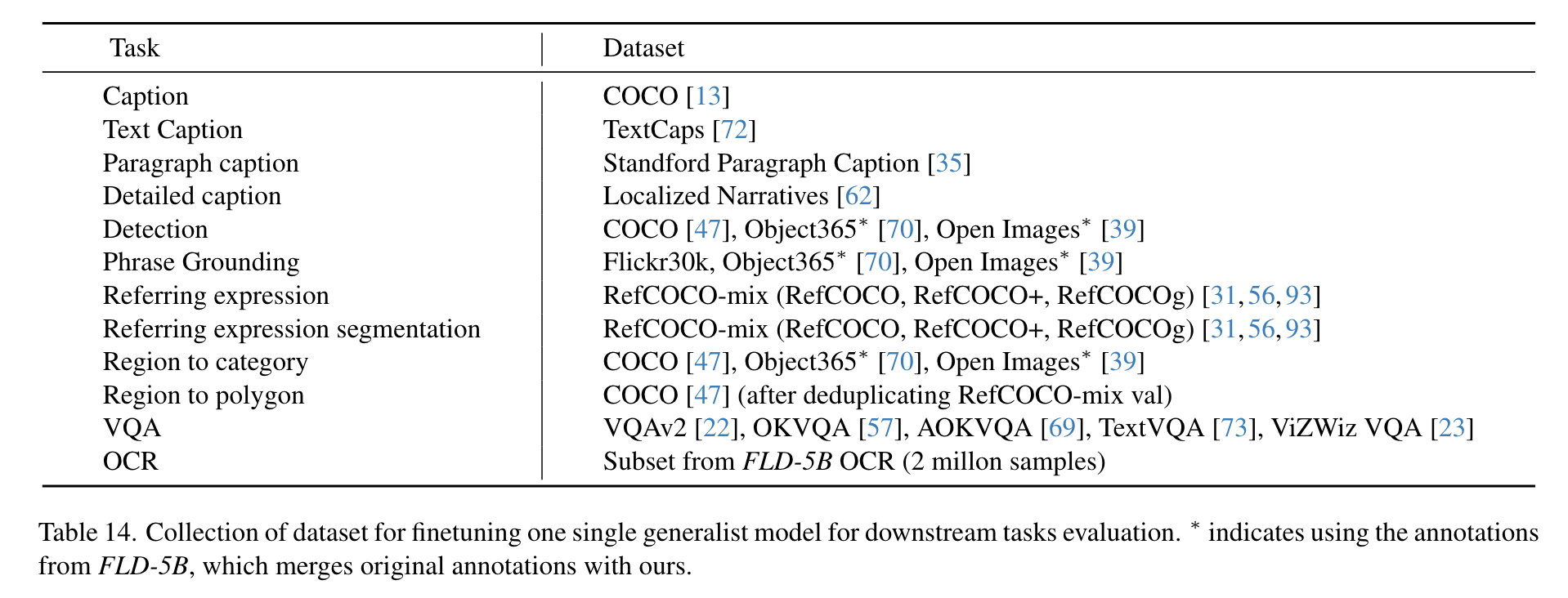
- model size
- Base: 232M
- Large: 771M
