(논문 요약) DINOv3 (Paper)
핵심 내용
- 데이터
- raw 17B images
- hierarchical k-means 적용하여 filtering (200M, 8M, 800k, 100k, 25k 개의 5-level)
- 1,689 M (named LVD-1689M)
7B param
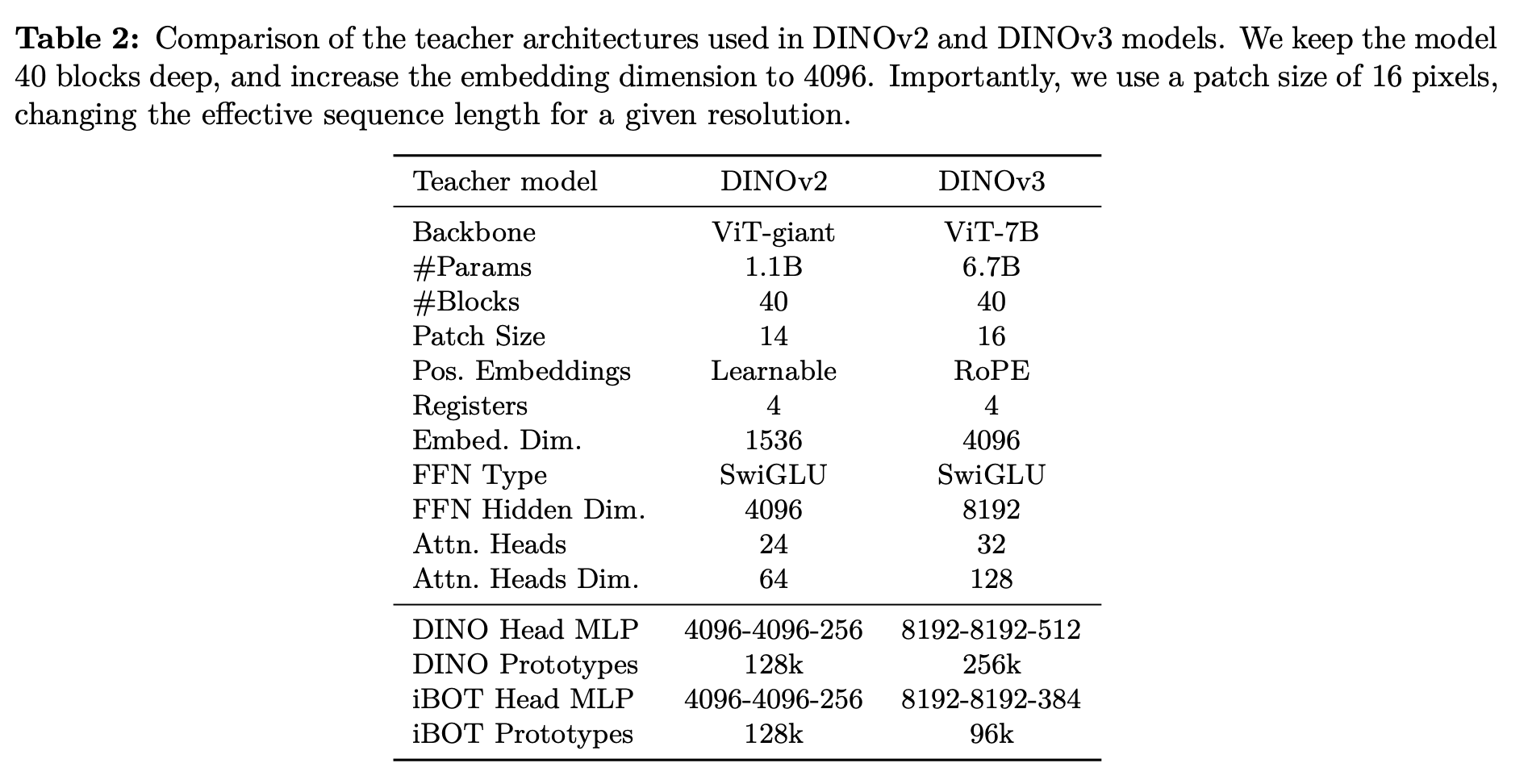
- objectives
- image-level (DINO loss)
- patch-level latent reconstruction (iBOT loss)
- Koleo regularizer: encourage the features within a batch to spread uniformly in the space
- Gram anchoring: old, new Gram matrix 간 Frobenius norm
- 학습이 진행될수록 global DINO loss 가 우세해짐.
- Gram anchoring 도입하여 이어서 학습시, iBOT loss 가 감소함.
결과
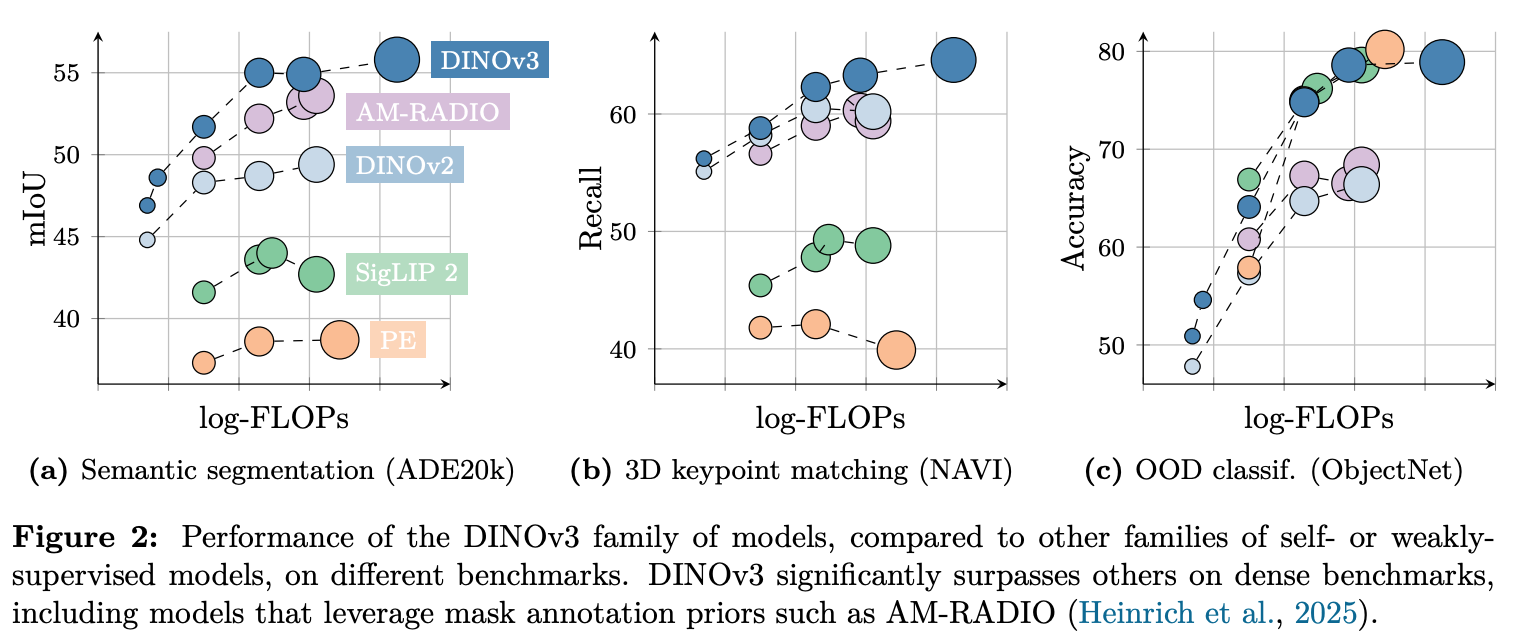
- downstream task 성능이 개선됨.
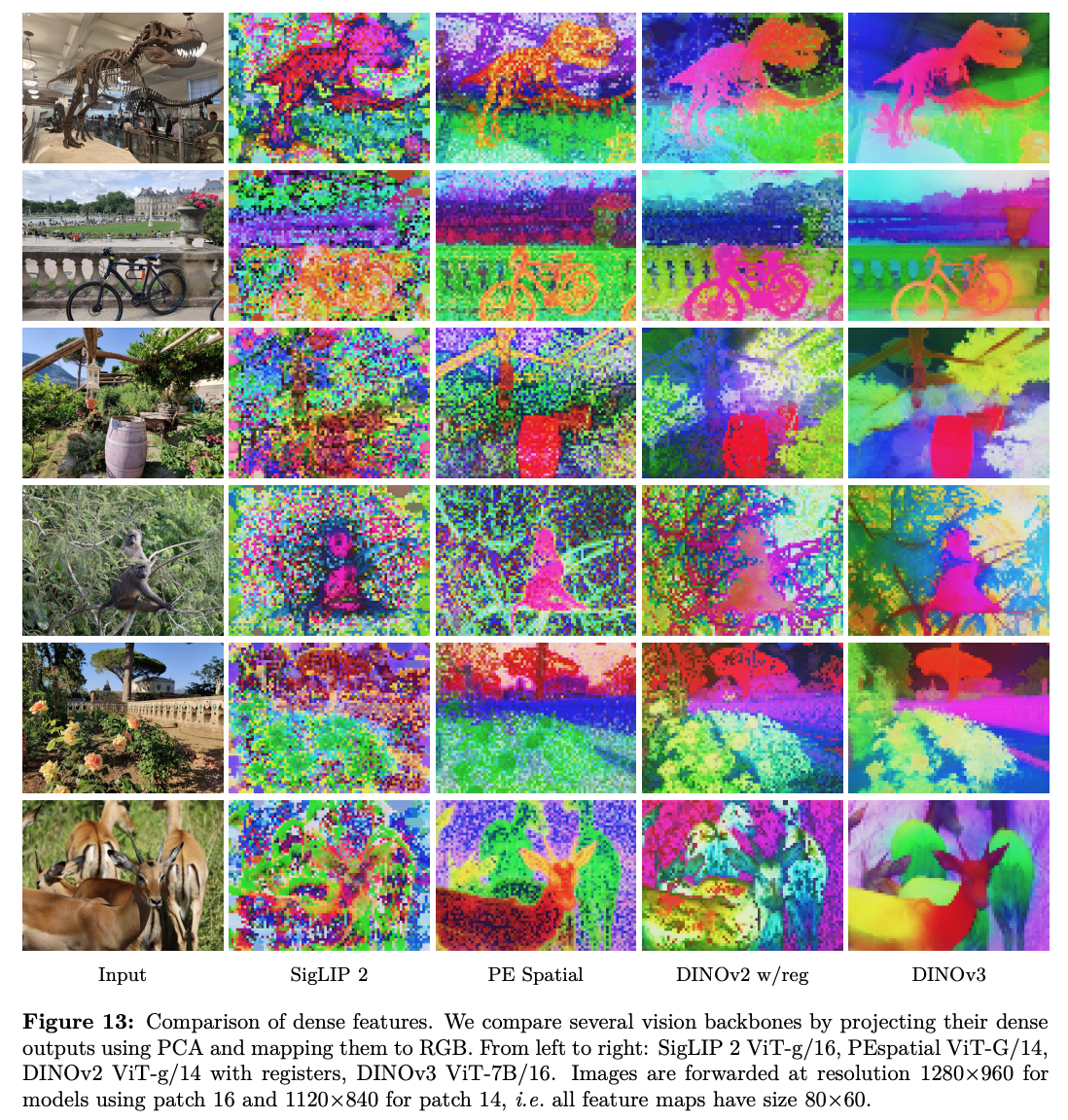
- PCA 결과 object boundary 가 타 모델보다 선명함.