(코드 탐색) vllm (v0.11.0) (github)
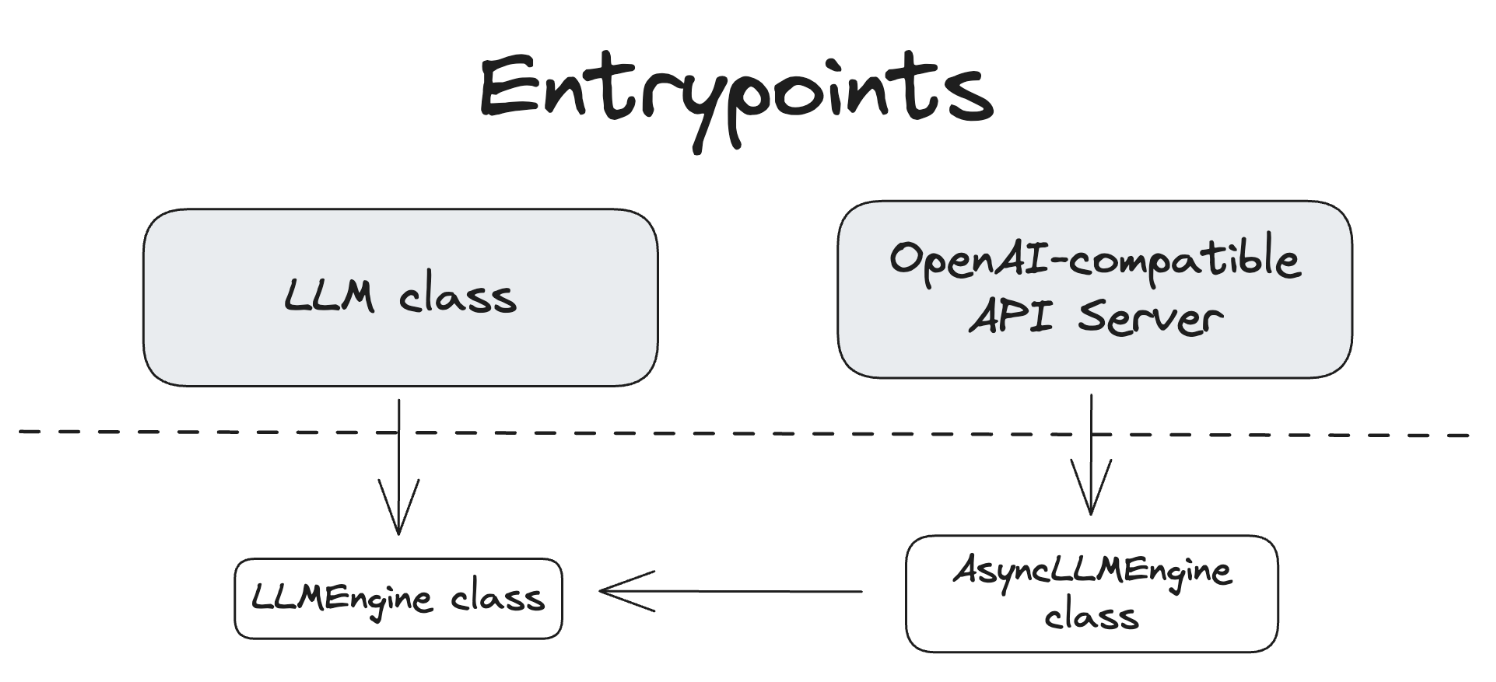
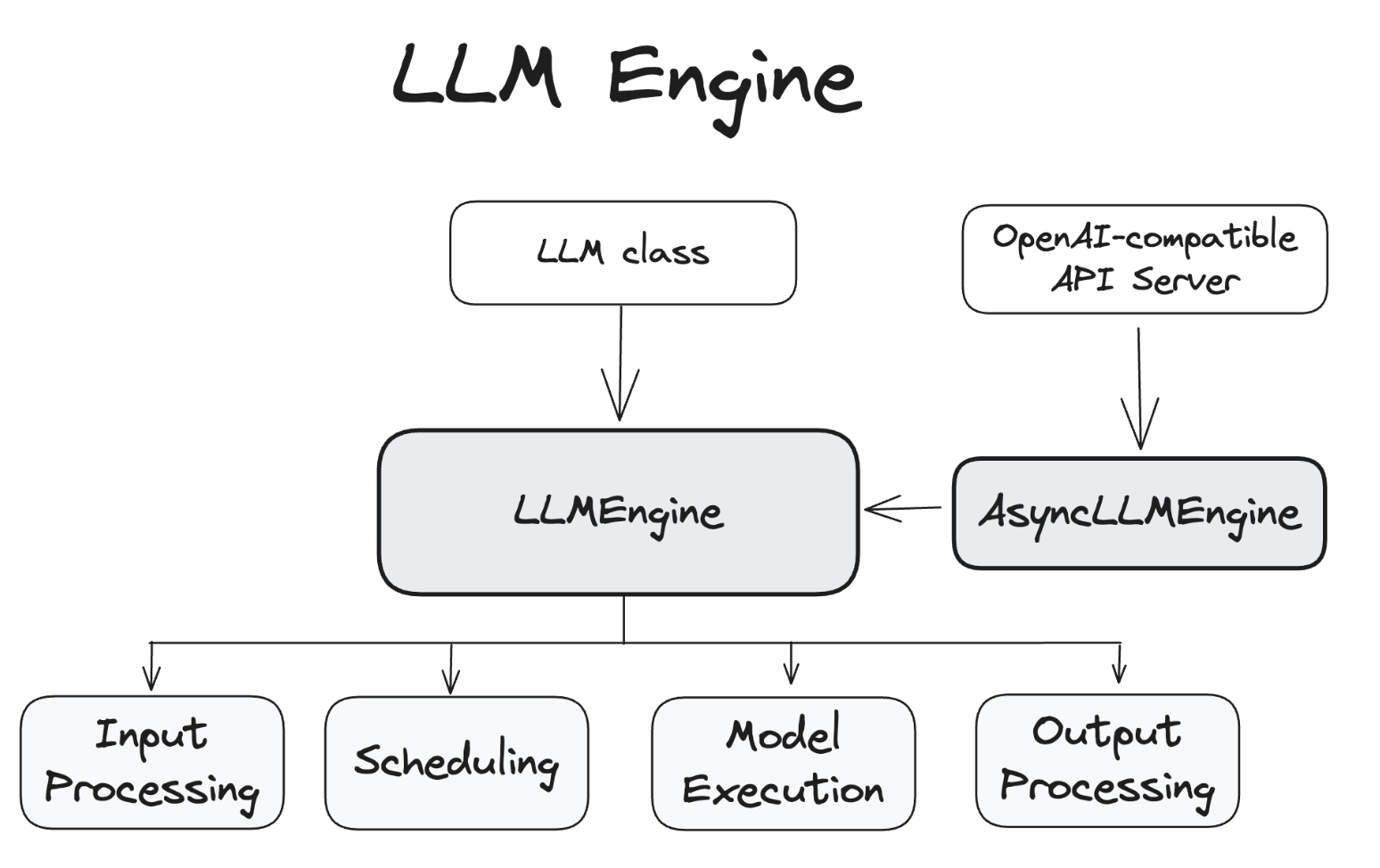
Class hierarchy
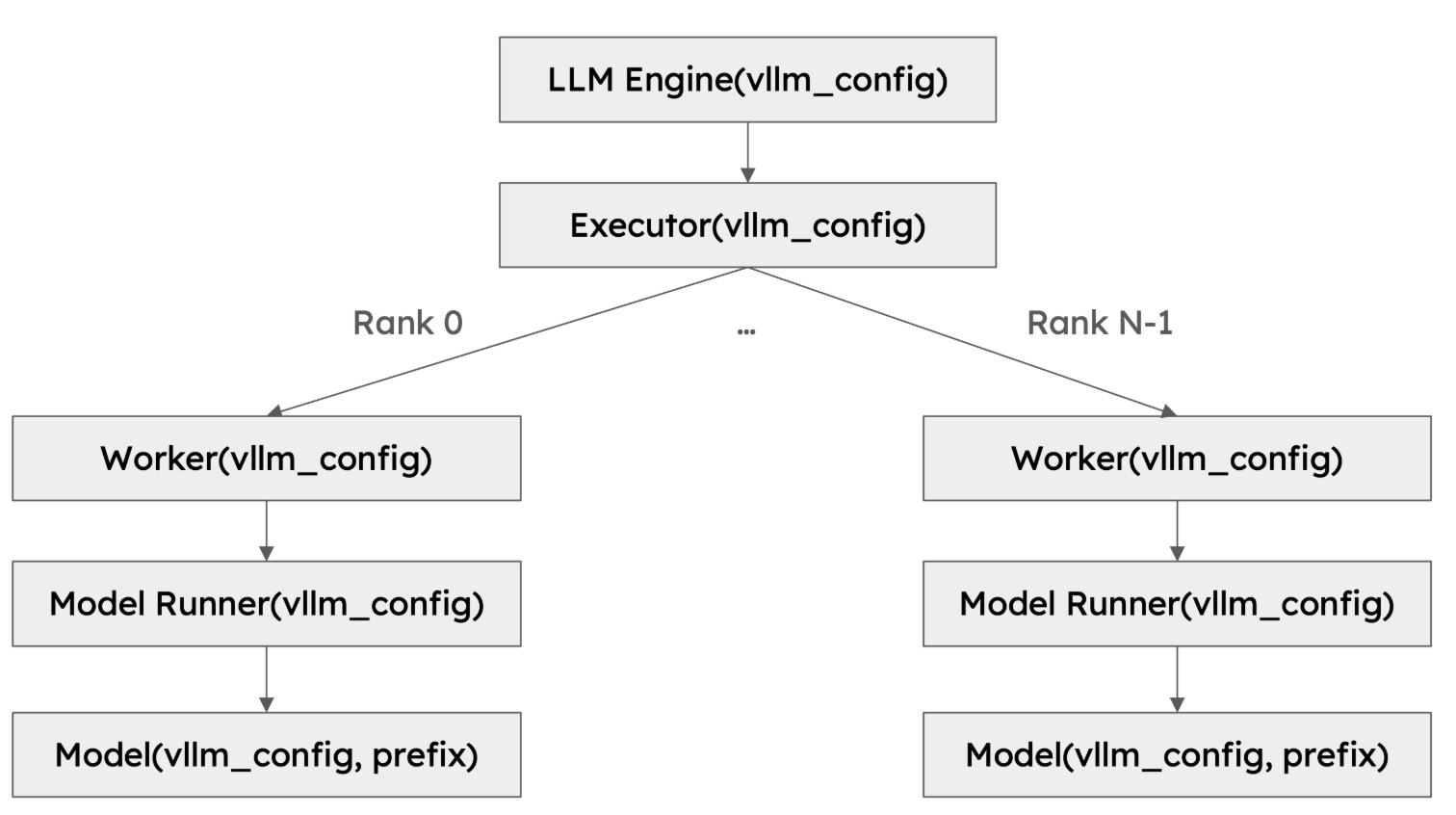
- VllmConfig class 가 공통 config 로 사용됨.
- EngineCore 가 Executor 를 가지고 있음.
GPU 를 사용하는 경우
- EngineCoreProc: handshake_address (query 를 주고 받는데 사용), model_executor 소유.
- model_executor.execute_model 함수 - return 값 == ModelRunnerOutput | None: - 내부에서 collective_rpc 로 gpu_worker 의 execute_model 함수 호출됨.
- gpu_worker 의 execute_model 함수
return 값 == ModelRunnerOutput AsyncModelRunnerOutput None - 내부에서 gpu_model_runner 의 execute_model 함수가 호출됨.
- gpu_model_runner 의 execute_model 함수
return 값 == ModelRunnerOutput AsyncModelRunnerOutput IntermediateTensors None - 내부에서 preprocess 및 forward 연산 수행 (e.g. CUDAGraphWrapper 의 __call__ 함수 호출)
- gpu_model_runner 의 load_model 함수에서 VllmBackend (attention backend config) 를 활용하여 torch.nn.Module.compile 호출하여 compiled model 을 소유.
- CUDAGraphWrapper 의 __call__ 함수
- ViT 의 경우, 내부에서 모델의 forward 가 호출됨
- LLM decoder 의 경우, PIECEWISEBackend 의 __call__ 함수가 호출됨.
- PIECEWISEBackend class 의 __call__ 함수
- 내부에서 torch._inductor.output_code.CompiledFxGraph 에서 실제 계산이 일어남.
KV Cache
- kv_cache_config 에 각 cache_group (e.g. layer) 별 spec 및 size 가 명시되어있음.
- gpu_model_runner 가 kv_caches 관리.
- initialize_kv_cache 함수
- kv_cache_config 를 바탕으로 cache 로 사용할 torch tensor 생성.
- 생성된 torch tensor 를 gpu_model_runner.kv_cache 와 compilation_config.static_forward_context.kv_cache 에 저장 (static_forward_context 는 Attention class)
- scheduler_output 안에 있는 block_id 가 지칭하는 torch.tensor 를 사용하여 attention 연산.
- initialize_kv_cache 함수
- BlockPool (v1/core/block_pool.py)
- 고정된 개수의 KVCacheBlock 들을 가지고 있음.
- KVCacheBlock 는 block_id, block_hash 정보를 가지고 있으며, 이를 통해 kv_cache 를 담당하는 torch.tensor 에 접근 가능함.
- reference count 를 통해 KVCacheBlock 들의 allocate 및 free 를 개념적으로 구현함.
- Scheduler 의 schedule 함수에서 새로운 block_id 들을 담은 scheduler_output 를 생성함.
- KVCacheBlock 이 부족한 경우, low-priority sequence 의 작업이 취소되고 KVCacheBlock 을 free 하여 사용함.
- gpu memory <-> main memory 의 cache eviction 은 존재하지 않음.
CUDA graphs
- In vLLM V1, piecewise cudagraphs are captured between attention operation (i.e. the first graph before any attention operation, the last graph after all the attention operation)
- cudagraphs are captured and managed by the compiler backend, and replayed when the batch size has corresponding cudagraph captured
# graph capture 예V시
bool graphCreated=false;
cudaGraph_t graph;
cudaGraphExec_t instance;
for(int istep=0; istep<NSTEP; istep++){
if(!graphCreated){
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(out_d, in_d);
}
cudaStreamEndCapture(stream, &graph);
cudaGraphInstantiate(&instance, graph, NULL, NULL, 0);
graphCreated=true;
}
cudaGraphLaunch(instance, stream);
cudaStreamSynchronize(stream);
}

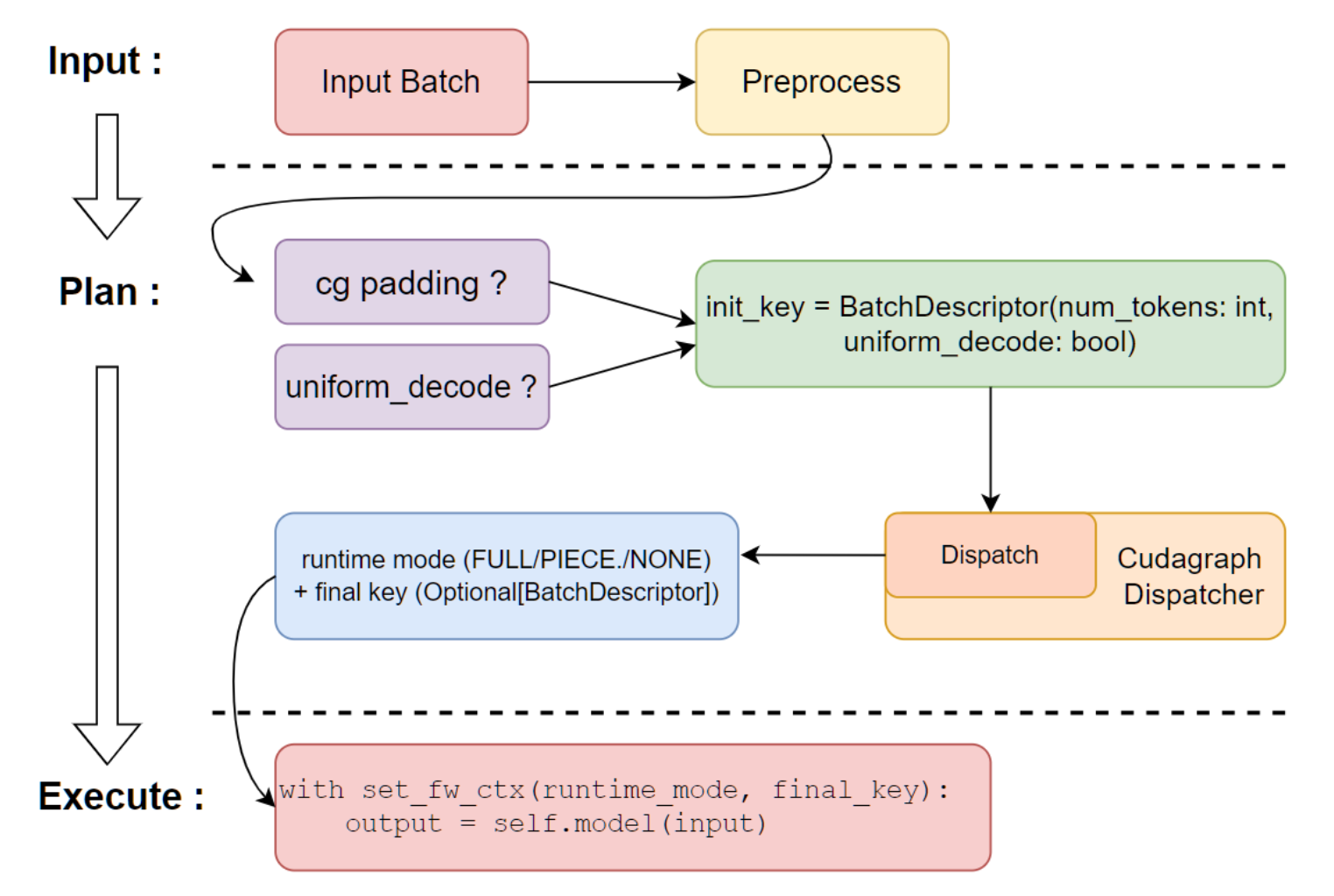
vLLM-torch.compile
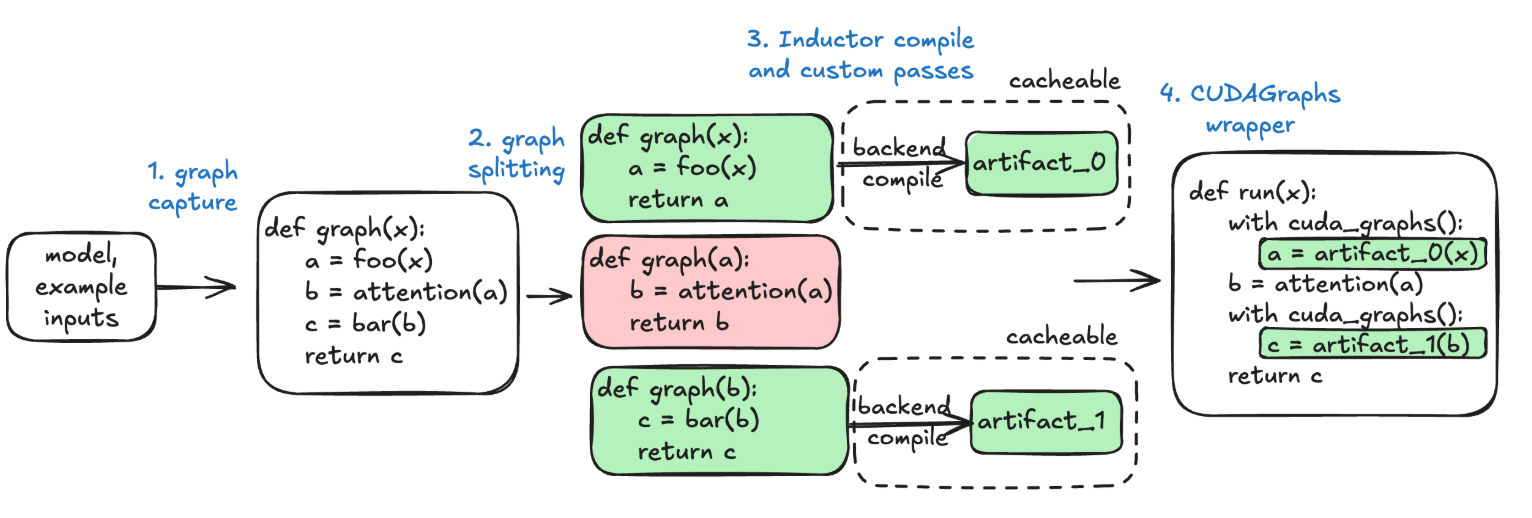
Overview
- full graph is captured via TorchDynamo
- TorchInductor to compile each graph into a compiled artifact (vLLM custom Inductor passes may be used to further optimize the graph)
- compiled artifact is saved to vLLM’s compile cache for future use
Compile cache
- modelinfos: 개별 모델별 hash 및 model_info (architecture name, vllm params) 에 관한 파일들이 들어있음.
- torch_compile_cache: 각 노드별 (e.g. rank_0_0) 다음 폴더들이 저장되어있음.
- inductor_cache
- triton_cache
- backbone
- computation_graph.py: GraphModule(torch.nn.Module) 의 forward 내부에서 실행되는 submodule 함수들이 구현되어있음.
- vllm_compile_cache.py: 각 layer 별, inductor_cache 의 torch.fx.graph 의 폴더 이름 및 python wrapper (compiled CUDA kernels 호출) 가 명시되어있음.
Implementation
- VllmBackend 가 CompilerManager 소유.
- CompilerManager (compilation/backends.py) 에 compile, save, load 가 구현되어있음.
(최초 compile cache 생성시) Huggingface 모델 로딩 방법
- config.json 에서 정보 취득.
- AutoTokenizer 로 tokenize.
- weight 는 huggingface AutoModel 이 아닌 torch 사용하여 vLLM 에서 별도로 구현.
Paged Attention
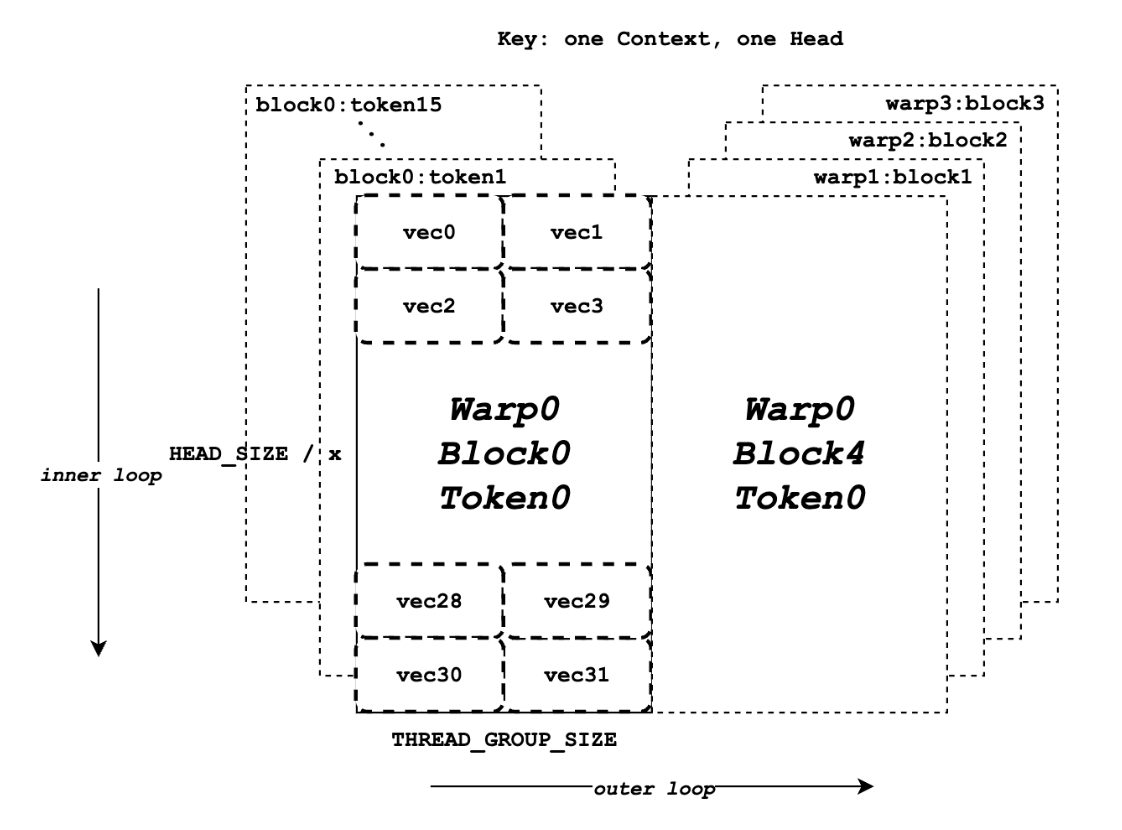
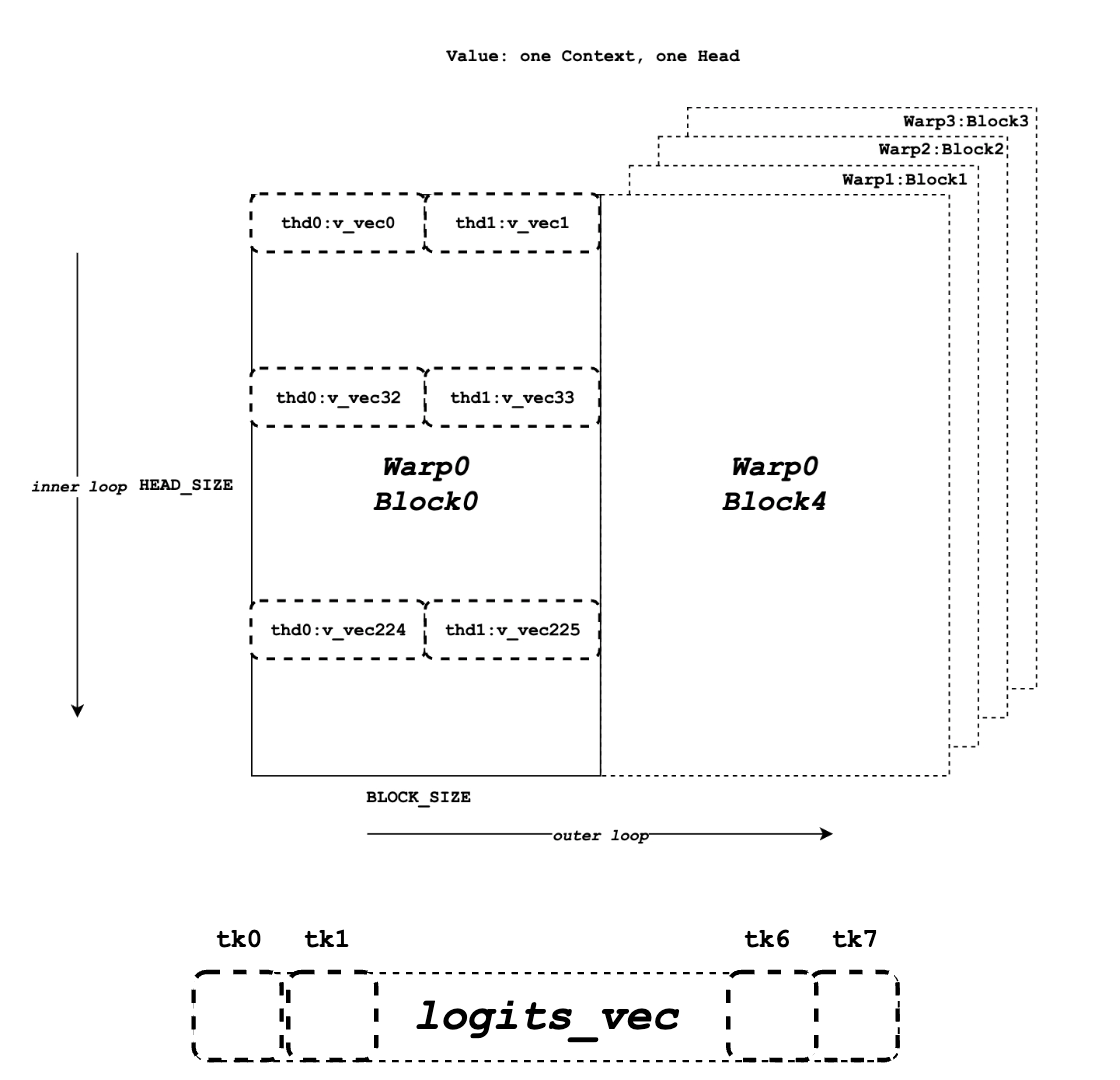
- scalar_t: e.g. FP32, FP16
- HEAD_SIZE: # elements at one head
- BLOCK_SIZE: # tokens at one head
- NUM_THREADS: # threads in each gpu thread block
- VEC_SIZE: # elements for query & key
- V_VEC_SIZE: # elements for value
- THREAD_GROUP_SIZE: # threads that fetches 1 query token (or 1 key token) at a time
- x: # total elements processed by one thread group
- PARTITION_SIZE: # tensor parallel GPUs
- WARP_SIZE: 32 threads per warp (warp processes the calculation between 1 query token and key tokens of one entire block at a time)
# query pointer
const scalar_t* q_ptr = q + seq_idx * q_stride + head_idx * HEAD_SIZE;
# query vector
__shared__ Q_vec q_vecs[THREAD_GROUP_SIZE][NUM_VECS_PER_THREAD];
# key pointer
const scalar_t* k_ptr = k_cache + physical_block_number * kv_block_stride
+ kv_head_idx * kv_head_stride
+ physical_block_offset * x;
# key vector
K_vec k_vecs[NUM_VECS_PER_THREAD]
# key
# output
scalar_t* out_ptr = out + seq_idx * num_heads * max_num_partitions * HEAD_SIZE
+ head_idx * max_num_partitions * HEAD_SIZE
+ partition_idx * HEAD_SIZE;


Plugins
- Plugins: user-registered code that vLLM executes (allows users to add custom features without modifying the vLLM codebase)
- plugins 종류: model, platform, pre/post-processing, logger
- IO Processor Plugins: pass a custom input to vLLM that is converted into one or more model prompts and fed to the model encode method.
- LoRA Resolver Plugins: dynamically load LoRA adapters at runtime.
Prefix caching
- cache the kv-cache blocks of processed requests, and reuse these blocks when a new request comes in with the same prefix as previous requests.
Hybrid KV Cache Manager
- Sliding window attention (sw) + full attention (full): gpt-oss, Gemma 2/3, Ministral, cohere, etc.
- Mamba + full: Bamba, Jamba, Minimax, etc.
- Local chunked attention + full: Llama4
P2P NCLL Connector
- Prefill 수행하는 gpu -> decode 수행하는 gpu
- ZeroMQ (ZMQ): asynchronous messaging library
- NCCL: NVIDIA Collective Communications Library
Dual Batch Overlap
- Data Parallel + Expert Parallel 인 경우 대상.
- 2 개의 CPU worker threads 가 ping-pong 하면서 계산-통신하면서 MoE layer 처리.
Fused MoE Kernel
- FusedMoE layer 의 expert parallelism (EP) 를 구현하기 위한 all2all communication backends 가 여럿 존재함 (e.g. triton, flashinfer).
- Modular Kernel 도 지원.